Постановка задачи
При большом числе неизвестных метод Гаусса становится весьма сложным в плане вычислительных и временных затрат. Поэтому иногда удобнее использовать приближенные (итерационные) численные методы, метод Якоби относится к таким.
В работе требуется решить систему линейных алгебраических уравнений вида:
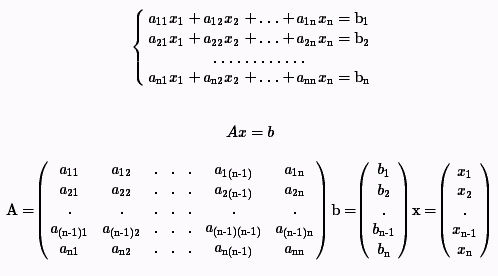
При предположении, что диагональные коэффициенты ненулевые.
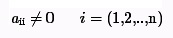
Метод решения
Решив 1-ое уравнение системы относительно x1 получим:
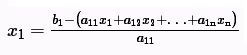
2-ое - относительно x2 , n-ое - относительно xn
В итоге эквивалентная система, в которой диагональные элементы строки выражены через оставщиеся.

Далее вводится некоторое начальное приближение - вектор x(0)=[b1/a11, ... ,bi/aii, ... ,bn/ann], затем используя x(1) находится x(2).
Данный процесс называется итерационным, условием окончания является достижение заданной точности (система сходится и есть решение) или прерывание процесса. Процесс прерывается когда число итераций превышает заданное допустимое количество, при этом система не сходится либо заданное количество итераций не хватило для достижения требуемой точности.
Итерационный процесс. Верхний индекс в скобках - номер итерации.

Если последовательность приближений (x(0),x(1),...,x(k+1),...) имеет предел
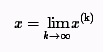
то этот предел является решением.
k=1,2,3,...N-1. , N-1 - заданное количество итераций
Достаточный признак сходимости метода Якоби:
Если в системе выполняется диагональное преобладание, то метод Якоби сходится.
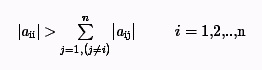
Критерий окончания итераций при достижении требуемой точности имеет вид:
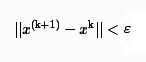
где ε - заданная точность вычисления
Параллельная схема
При распараллеливании алгоритма предполагается, что размерность системы больше числа процессоров. Каждый процессор считает “свои” элементы вектора Х=(x1,x2,x3,...,xn).
Перед началом выполнения метода на каждый процессор рассылаются необходимые данные:
1) размерность системы N
2) начальное приближение X0
3) строки матрицы A
4) элементы вектора свободных членов b.
После получения необходимой информации каждый процессор будет вычислять соответствующие компоненты вектора X и передавать их главному процессору. Главный процессор при получении очередного приближения решения Xk должен сравнить его с предыдущим приближением Xk-1. Если норма разности этих векторов:
||Xk – Xk-1|| = max {|Xk,i – Xk,i-1|, i = 1,1,…n}
окажется меньше или равной заданной точности (ε), то вычисления закончатся. В противном случае вектор Xk поэлементно будет разослан всем процессам и будет вычисляться очередное приближение решения.
Анализ эффективности
Время, затраченное на последовательное выполнение алгоритма, выражается следующей формулой:
T = k * (2*n^2 - n), где k – число выполненных итераций, а n – число уравнений.
Время, затраченное на параллельное выполнение алгоритма на p процессорах без учета затрат на передачу данных, выражается формулой:
T(p) = k/p * (2*n^2 - n)
Тогда ускорение равно:
S = T(1) / T(p) = p
Эффективность:
E = T1 / p*Tp = 1
Разработанный способ параллельных вычислений позволяет достичь идеальных показателей ускорения и эффективности.
Определим время, затрачиваемое на передачу данных. Для этого используем модель Хокни.
Первоначальная рассылка данных требует следующее время:
Tcomm1 = (p-1) * (4*alfa + (n^2 / p + n) / betta), где alfa - латентность, betta - пропускная способность сети
Передача данных, выполняемая в итерационном процессе, затрачивает следующее время:
Tcomm2 = k * (p-1) * (3*alfa + (n / p + n) / betta), где k - количество выполненных итераций
В итоге общее время передачи данных выражается формулой:
Tcomm = (p-1) * (4*alfa + (n^2 / p + n) / betta) + k * (p-1) * (3*alfa + (n / p + n) / betta)
Это время зависит от числа итераций. Как правило, их количество меньше числа уравнений n. Значит время на передачу данных можно оценить величиной:
Tcomm = O(n^2)
В свою очередь и ко времени выполнения алгоритма применима та же оценка:
T = O(n^2)
Если число итераций будет сравнимо с n, то для времени выполнения алгоритма будет справедлива уже другая оценка:
T = O(n^3)
Демонстрация
На каждой итерации итерации вычисление (k+1)-ого вектора происходит по следующей схеме:
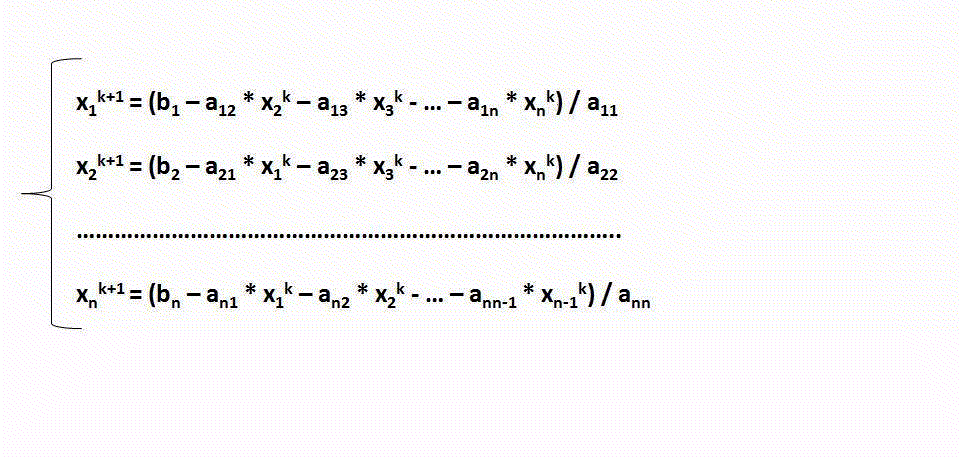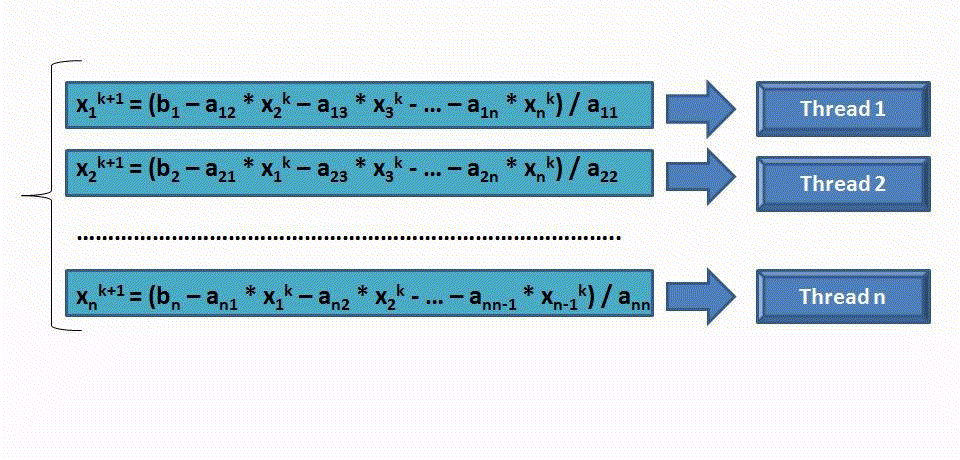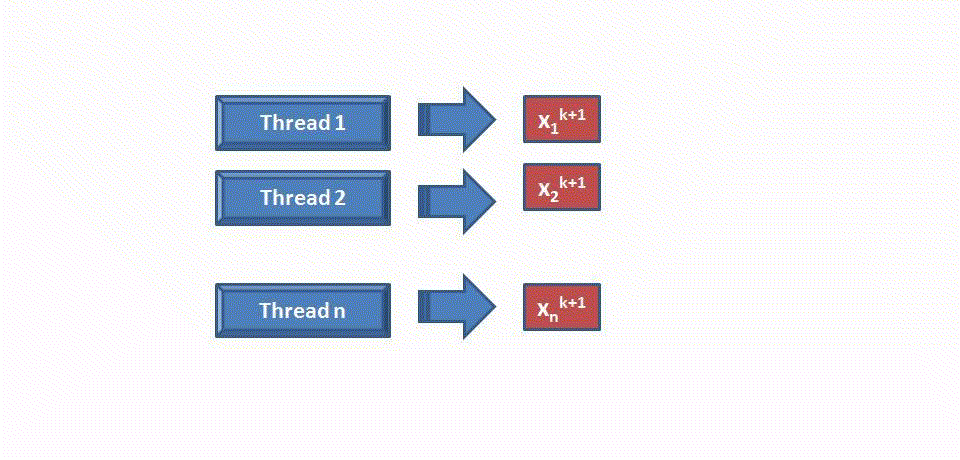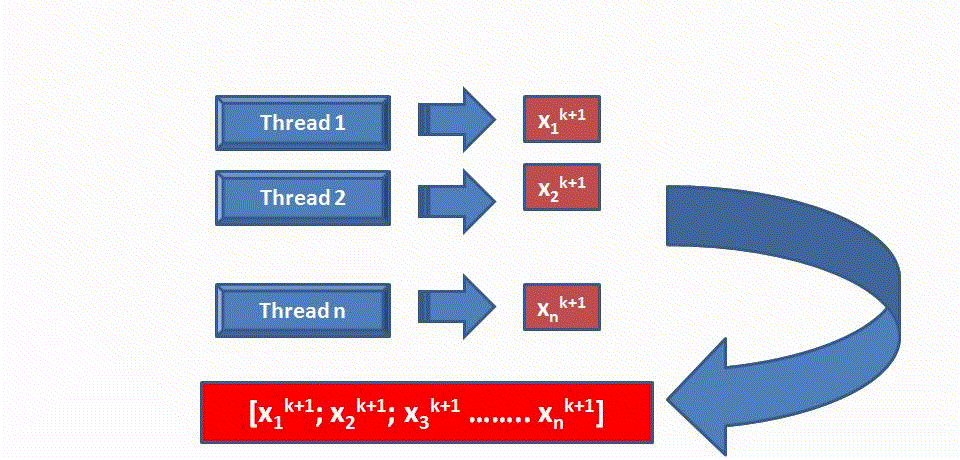
Результаты вычислительных экспериментов
Эксперименты проводились на следующем компьютере:
Процессор Intel(R) Core(TM) i7-2630QM CPU @ 2.00GHz, ОС Windows 8 64-bit.
Результаты программы(MPI)
|
Размер матрицы |
Последовательный алгоритм (1 процесс) |
4 процесса |
2 процесса |
|
Параллельный алгоритм (мс) |
Теор. время паралл. алгоритма (мс) |
Ускорение |
Параллельный алгоритм (мс) |
Теор. время паралл. алгоритма (мс) |
Ускорение |
|
3000*3000 |
33 |
15 |
8,25 |
2,2 |
18 |
16,5 |
1,8 |
|
6000*6000 |
136 |
59 |
34 |
2,3 |
72 |
68 |
1,8 |
|
9000*9000 |
314 |
132 |
78,5 |
2,37 |
163 |
157 |
1,9 |
Результаты программы(OpenMP)
Эксперименты проводились на следующих компьютерах:
1) Процессор Intel(R) Core(TM) i7-2630QM CPU
@ 2.00GHz, ОС Windows 8 64-bit.
2) Процессор AMD Phenom(tm) II X4 945, ОС Windows 7 64-bit.
3) Процессор AMD Turion(tm) II P540 Dual-Core Processor 2.40GHz, ОС Windows 7 64-bit.
Каждое значение, представленное в данной таблице, является средним временем на основе 25 экспериментов.
|
Размер матрицы |
8 процессов |
4 процесса |
2 процесса |
|
Последовательный алгоритм (мс) |
Параллельный алгоритм (мс) |
Теор. время паралл. алгоритма (мс) |
Ускорение |
Последовательный алгоритм (мс) |
Параллельный алгоритм (мс) |
Теор. время паралл. алгоритма (мс) |
Ускорение |
Последовательный алгоритм (мс) |
Параллельный алгоритм (мс) |
Теор. время паралл. алгоритма (мс) |
Ускорение |
|
3000*3000 |
77 |
13 |
10 |
5,92 |
90 |
26 |
23 |
3,46 |
127 |
98 |
64 |
1,29 |
|
6000*6000 |
294 |
46 |
37 |
4,22 |
350 |
99 |
88 |
3,89 |
474 |
370 |
237 |
1,28 |
|
9000*9000 |
631 |
90 |
79 |
4,01 |
801 |
269 |
200 |
2,98 |
1189 |
953 |
595 |
1,24 |
|
12000*12000 |
1109 |
159 |
139 |
6,97 |
1439 |
565 |
360 |
2,55 |
2020 |
1789 |
1010 |
1,12 |
|
15000*15000 |
1721 |
254 |
215 |
6,78 |
2451 |
920 |
613 |
2,66 |
2912 |
2644 |
1456 |
1,1 |
Код программы (OpenMP)
Файл "Jacobi.cpp" |
#include "stdafx.h"
#include "EquationsLinearSystem.h"
int _tmain(int argc, _TCHAR* argv[])
{
int dimension;
printf("Input dimension of Matrix\n");
scanf("%d", &dimension);
EquationsLinearSystem* linearSystem = new EquationsLinearSystem(dimension);
clock_t start = clock();
linearSystem->Solve();
clock_t finish = clock();
printf("Time = %fsec.", (double)(finish - start)/CLOCKS_PER_SEC);
getch();
return 0;
} |
Файл "EquationsLinearSystem.h" |
#pragma once
class EquationsLinearSystem
{
private:
int Dimension;
int* A;
int* B;
public:
EquationsLinearSystem(int N)
{
srand(time(0));
Dimension = N;
A = new int[N*N];
B = new int[N];
this->AutomaticalInitialization();
}
public:
~EquationsLinearSystem(void)
{
delete A;
delete B;
}
private:
void AutomaticalInitialization(void)
{
#pragma omp parallel for
for (int I=0; Idouble Sum = 0;
for (int J=0; Jif (I!=J)
{
A[I*Dimension + J] = rand()%18 - 9;
Sum += this->Absolute(A[I*Dimension + J]);
}
}
int sign;
if (rand() > 16000)
sign = 1;
else
sign = -1;
A[I*Dimension + I] = Sum * (rand()/32767.0 + 1) * sign;
B[I] = rand()%18 - 9;
}
}
private:
void CopyArray(double* Source, double* newArray)
{
for (int I=0; InewArray[I] = Source[I];
}
private:
double Absolute(double a)
{
if (a > 0)
return a;
else
return -a;
}
private:
int Absolute(int a)
{
if (a > 0)
return a;
else
return -a;
}
private:
double MaxDifference(double* X1, double* X2)
{
double Result = 0.0;
#pragma omp parallel for shared(Result)
for (int I = 0; I < Dimension; I++)
{
double ValueOfCurrentIteration = this->Absolute(X1[I] - X2[I]);
if (ValueOfCurrentIteration > Result) Result = ValueOfCurrentIteration;
}
return Result;
}
public:
void Solve(void)
{
double* X = new double[Dimension];
double* X_last = new double[Dimension];
for (int I=0; I<Dimension; I++)
X_last[I] = B[I]/A[I*Dimension + I];
const double Epsilon = 0.0001;
double maxDifference;
int IterationCounter = 1;
do
{
if (IterationCounter > 1)
this->CopyArray(X, X_last);
#pragma omp parallel for
for (int I = 0; I < Dimension; I++)
{
X[I] = B[I];
for (int J = 0; J < Dimension; J++)
{
if (I != J)
X[I] -= A[I*Dimension + J] * X_last[J];
}
X[I] = X[I] / A[I*Dimension + I];
X[0];
X[1];
}
maxDifference = MaxDifference(X, X_last);
IterationCounter++;
} while (maxDifference > Epsilon);
}
}; |
Файл "EquationsLinearSystem.h" |
#pragma once
#include "targetver.h"
#include <stdio.h>
#include <tchar.h>
#include <math.h>
#include <stdlib.h>
#include <time.h>
#include <omp.h> |
Код программы (MPI)
Файл "Jacobi.cpp" |
#include "stdafx.h"
#include "mpi.h"
#include <stdio.h>
#include <math.h>
#include <time.h>
#include <iostream>
using namespace std;
void KeyboardDataInit(double *m,double *v,int size){
for(int i=0;i<size;i++){
for (int j=0;j<size;j++){
cout<<"a["<<i+1<<"]"<<'['<<j+1<<"]=";
cin>>m[i*size+j];
}
cout<<"b["<<i+1<<"]= ";
cin>>v[i];
}
}
void RandomDataInit(double *m,double *v,int size){
srand(time(0));
for (int i=0; i 16000)
sign = 1;
else
sign = -1;
m[i*size+i] = sign *sum*(rand()/32767.0 + 1) ;
v[i] = rand()%18 - 9;
}
}
int _tmain(int argc, char* argv[])
{
double* pA;
double* pB;
double* pX;
double* pProcRowsA;
double* pProcRowsB;
double* pProcTempX;
int Size, RowNum, ProcNum, ProcRank;
double Eps,Norm,MaxNorm;
double Start, Finish, Dt;
MPI_Init(&argc, &argv);
MPI_Comm_size(MPI_COMM_WORLD, &ProcNum);
MPI_Comm_rank(MPI_COMM_WORLD, &ProcRank);
if (ProcRank==0){
cout<<"Input the dimension ";
cin >> Size;
}
MPI_Bcast(&Size, 1, MPI_INT, 0, MPI_COMM_WORLD);
RowNum = Size/ProcNum;
Eps=0.001;
pX = new double[Size];
pProcRowsA = new double [RowNum*Size];
pProcRowsB = new double [RowNum];
pProcTempX = new double [RowNum];
if (ProcRank == 0){
pA = new double [Size*Size];
pB = new double [Size];
RandomDataInit(pA, pB, Size);
//KeyboardDataInit(pA, pB, Size);
for (int i=0;i Norm)
Norm = fabs(pX[ProcRank*RowNum+i] - pProcTempX[i]);
}
MPI_Reduce(&Norm,&MaxNorm, 1, MPI_DOUBLE, MPI_MAX, 0, MPI_COMM_WORLD);
MPI_Bcast(&MaxNorm, 1, MPI_DOUBLE, 0, MPI_COMM_WORLD);
MPI_Allgather(pProcTempX, RowNum, MPI_DOUBLE, pX, Size, MPI_DOUBLE, MPI_COMM_WORLD);
}
while (MaxNorm > Eps);
Finish = MPI_Wtime();
if (ProcRank == 0){
cout< |
Новости
22.10.2012
04.09.2012
05.04.2012
06.03.2012
02.03.2012
|
 |
|
|




