Последовательный алгоритм Прима
Алгоритм начинает работу с произвольной вершины графа, выбираемой в качестве
корня дерева, и в ходе последовательно выполняемых итераций расширяет
конструируемое дерево до МОД. Пусть VT есть множество вершин, уже включенных
алгоритмом в МОД, а величины di, 1in, характеризуют дуги минимальной длины от
вершин, еще не включенных в дерево, до множества VT, т.е.

(если для какой-либо вершины i VT не существует
ни одной дуги в VT, значение di устанавливается равным ∞). В начале работы
алгоритма выбирается корневая вершина МОД s и полагается VT={s}, ds=0.
VT не существует
ни одной дуги в VT, значение di устанавливается равным ∞). В начале работы
алгоритма выбирается корневая вершина МОД s и полагается VT={s}, ds=0.
Действия, выполняемые на каждой итерации алгоритма Прима, состоят в
следующем:
определяются значения величин di для всех вершин, еще не
включенных в состав МОД;
выбирается вершина t графа G, имеющая дугу
минимального веса до множества VTt:dt, iVT;
вершина t включается в VT.
После выполнения n-1 итерации метода МОД будет сформировано. Вес этого дерева
может быть получен при помощи выражения
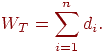
Разделение вычислений на независимые части
Оценим возможности параллельного выполнения рассмотренного алгоритма
нахождения минимально охватывающего дерева.
Итерации метода должны выполняться последовательно и, тем самым, не могут
быть распараллелены. С другой стороны, выполняемые на каждой итерации алгоритма
действия являются независимыми и могут реализовываться одновременно. Так,
например, определение величин di может осуществляться для каждой вершины графа в
отдельности, нахождение дуги минимального веса может быть реализовано по
каскадной схеме и т.д.
Распределение данных между процессорами вычислительной системы должно
обеспечивать независимость перечисленных операций алгоритма Прима. В частности,
это может быть реализовано, если каждая вершина графа располагается на
процессоре вместе со всей связанной с вершиной информацией. Соблюдение данного
принципа приводит к тому, что при равномерной загрузке каждый процессор pj, 1jp,
должен содержать:
набор вершин

соответствующий этому набору блок из k величин
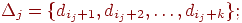
вертикальную полосу матрицы смежности графа G из k соседних столбцов
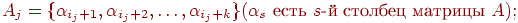
общую часть набора Vj и формируемого в процессе вычислений множества вершин
VT.
Как итог можем заключить, что базовой подзадачей в параллельном алгоритме
Прима может служить процедура вычисления блока значений Δj для вершин Vj матрицы
смежности A графа G.
С учетом выбора базовых подзадач общая схема параллельного выполнения
алгоритма Прима будет состоять в следующем:
определяется вершина t графа G,
имеющая дугу минимального веса до множества VT. Для выбора такой вершины
необходимо осуществить поиск минимума в наборах величин di, имеющихся на каждом
из процессоров, и выполнить сборку полученных значений на одном из
процессоров;
номер выбранной вершины для включения в охватывающее дерево
передается всем процессорам;
обновляются наборы величин di с учетом
добавления новой вершины.
Таким образом, в ходе параллельных вычислений между процессорами выполняются
два типа информационных взаимодействий: сбор данных от всех процессоров на одном
из процессоров и передача сообщений от одного процессора всем процессорам
вычислительной системы.




{kind=link}