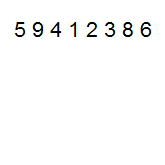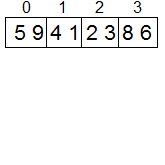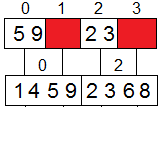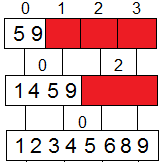Выполнить реализацию параллельного алгоритма быстрой
сортировки по одной из приведенных схем. Определить оценки показателей ускорения
и эффективности для реализованного метода параллельных
вычислений.
Метод решения
Параллельное обобщение алгоритма быстрой сортировки наиболее
простым способом может быть получено для вычислительной системы с топологией в
виде N-мерного гиперкуба (т.е. p=2N). Пусть, как и ранее, исходный набор данных
распределен между процессорами блоками одинакового размера n/p; результирующее
расположение блоков должно соответствовать нумерации процессоров гиперкуба.
Возможный способ выполнения первой итерации параллельного метода при таких
условиях может состоять в следующем: • выбрать
каким-либо образом ведущий элемент и разослать его по всем процессорам системы;
• разделить на каждом процессоре имеющийся блок
данных на две части с использованием полученного ведущего
элемента; • образовать пары процессоров, для
которых битовое представление номеров отличается только в позиции N, и
осуществить взаимообмен данными между этими процессорами; в результате таких
пересылок данных на процессорах, для которых в битовом представлении номера бит
позиции N равен 0, должны оказаться части блоков со значениями, меньшими
ведущего элемента; процессоры с номерами, в которых бит N равен 1, должны
собрать, соответственно, все значения данных, превышающие значение ведущего
элемента. В результате выполнения такой итерации сортировки исходный набор
оказывается разделенным на две части, одна из которых (со значениями меньшими,
чем значение ведущего элемента) располагается на процессорах, в битовом
представлении номеров которых бит N равен 0. Таких процессоров всего р/2 и,
таким образом, исходный N-мерный гиперкуб оказывается разделенным на два
гиперкуба размерности (N-1). К этим подкубам, в свою очередь, может быть
параллельно применена описанная выше процедура. После N-кратного повторения
подобных итераций для завершения сортировки достаточно упорядочить блоки данных,
получившиеся на каждом отдельном процессоре вычислительной системы.
Эффективность параллельного метода быстрой сортировки, как и в последовательном
варианте, во многом зависит от успешности выбора значений ведущих элементов.
Определение общего правила для выбора этих значений является достаточно трудной
задачей; сложность такого выбора может быть снижена, если выполнить упорядочение
локальных блоков процессоров перед началом сортировки и обеспечить однородное
распределение сортируемых данных между процессорами вычислительной
системы.
Оценка сложности
В качестве отностительной оценки сложности параллельного
алгоритма используем ускорение
S=T1/Tp
где, Tp - время решения
задачи на p процессорах.
T1 = n*log(n).
Вычислительная сложность (время решения задачи) параллельного
алгоритма быстрой сортировки для p потоков определяется выражением:
Tp = N(2n/p) +
n/p * log(n/p),
где первая часть определяет общую трудоемкость всех операций
выбора ведущего элемента и разделения блоков согласно этому элементу, а вторая –
трудоемкость локальной сортировки блоков на последней итерации алгоритма.
Тогда S = n*log(n) / (N(2n/p) + n/p *
log(n/p)).