Введение
Сортировка является одной из типовых проблем обработки данных и обычно понимается как задача размещения элементов неупорядоченного набора значений
S = {a1, a2, ..., an}
в порядке монотонного возрастания или убывания
S ~ S'={(a1', a2', ..., an'): a1'<= a2' <=... <= an'}
Возможные способы решения этой задачи широко обсуждаются в литературе; в данной работе рассмотрен метод сортировки слиянием.
Постановка задачи
Написать программу, сортирующую массив элементов с помощью сортировки слиянием с использованием методов параллельного программирования. Для этого разработать параллельный алгоритм данной сортировки. Затем сравнить время выполнения на нескольких процессах, определить ускорение.
Программа должна использовать интерфейс MPI для эффективной работы на системах с распределенной памятью.
Описание алгоритма
Процедура слияния требует два отсортированных массива. Заметив, что массив из одного элемента по определению является отсортированным, мы можем осуществить сортировку следующим образом:
1. Разбить имеющиеся элементы массива на пары и осуществить слияние элементов каждой пары, получив отсортированные цепочки длины 2 (кроме, быть может, одного элемента, для которого не нашлось пары);
2. Разбить имеющиеся отсортированные цепочки на пары, и осуществить слияние цепочек каждой пары;
3. Если число отсортированных цепочек больше единицы, перейти к шагу 2.
Проще всего формализовать этот алгоритм рекурсивным способом, хотя, конечно, есть и несложные итерационные методы. Функция Merge сортирует участок массива от элемента с номером a до элемента с номером b:
void merge (double* a, int n1, int n2)
{
int m = (n1 + n2) / 2;
if (n1 == n2)
return;
else
{
merge (a, n1, m);
merge (a, m+1, n2);
bond (a, n1, m, n2);
}
}
Нетривиальным этапом является соединение двух упорядоченных массивов в один(bond). Основная идея состоит в том, чтобы поочерёдно сравнивать элементы этих массивов. То есть, на первом шаге сравнить первые элементы двух массивов, выбрать из них наименьший и отправить его в результирующий массив. Затем уже сравнить элемент, не попавший в основной массив, со следующим элементом во втором массиве. Делается это до тех пор, пока один массив не станет пустым. Затем, оставшиеся элементы из непустого массива передаются в конец результирующего массива.
Время работы сортировки слиянием составляет О(n*log2(n)). Пример работы процедуры показан на рисунке:
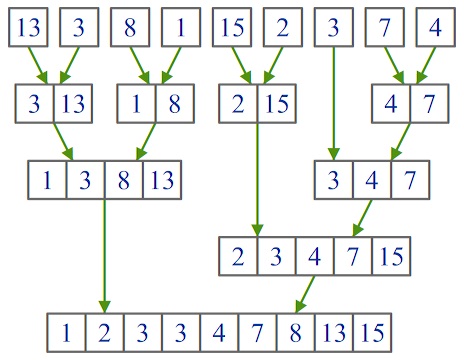
Параллельная реализация
Суть параллельной реализации данной сортировки заключается в следующем: для начала выполняется передача, разбиение массива элементов по всем процессам. Каждый процесс параллельно сортирует свой массив последовательным алгоритмом.
MPI_Bcast (&n, 1, MPI_INT, 0, MPI_COMM_WORLD);
if (rank < n%size)
k = n/size + 1;
else
k = n/size;
double *x = new double [k];
MPI_Scatterv(a, raz, dist, MPI_DOUBLE,
x, k, MPI_DOUBLE,
0, MPI_COMM_WORLD);
merge(x, 0, k - 1);
После этого мы имеем несколько отсортированных массивов. Теперь задача состоит в слиянии этих массивов в один, результирующий. Слияние будет проводиться итерационно: на первом шаге процессы делятся на пары, и правый массив передаёт свои данные левому. Тот процесс сортирует их, используя функцию bond. На втором шаге также объединяем процессы в пары, но только те, которые были левыми на первом шаге. Опять, также, правый процесс передаёт свои данные левому, а тот их сортирует. Это выполняется до тех пор, пока не останется один процесс. Его массив и будет результатом параллельной сортировки.
int s = size, m = 1;
while (s > 1)
{
s = s/2 + s%2;
if ((rank-m)%(2*m) == 0)
{
MPI_Send (&k, 1, MPI_INT,
rank-m, 0, MPI_COMM_WORLD);
MPI_Send (x, k, MPI_DOUBLE,
rank-m, 0, MPI_COMM_WORLD);
}
if ((rank%(2*m) == 0) && (size - rank > m))
{
MPI_Status status;
int k1;
MPI_Recv (&k1, 1, MPI_INT,
rank+m, MPI_ANY_TAG, MPI_COMM_WORLD, &status);
double *y = new double [k + k1];
MPI_Recv (y, k1, MPI_DOUBLE,
rank+m, MPI_ANY_TAG, MPI_COMM_WORLD, &status);
for (int i = 0; i < k; i++)
y[i+k1] = x[i];
bond(y, 0, k1-1, k+k1-1);
x = new double [k1 + k];
for (int i = 0; i < k+k1; i++)
x[i] = y[i];
k = k + k1;
}
m = 2*m;
}
Тестирование
Рассмотрим работу алгоритма на примере. Пусть дан массив из 15 элементов и 4 процесса.
1. На первом шаге объявляем массив в 0-ом процессе, записываем в него элементы и делим этот массив между всеми процессами.
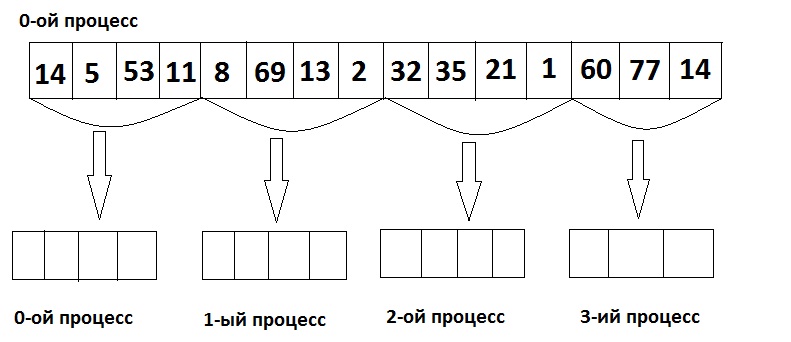
2. Сортируем в каждом процессе массив.

3. Теперь поочерёдно сливаем массивы из процессов в один.
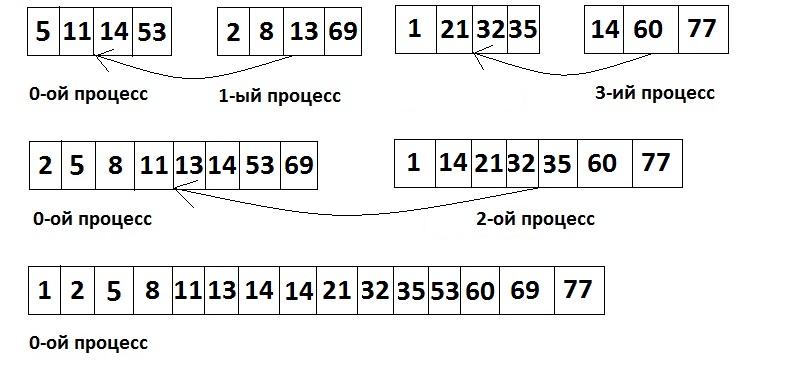
Анализ эффективности
Как уже упоминалось выше, трудоёмкость выполнения последовательного алгоритма сортировки слияния равна О(n*log2(n)).
Теперь определим трудоёмкость параллельного алгоритма. После передачи элементов всем процессам они выполняют сортировку последовательным алгоритом слияния. Значит трудоёмкость t1 равна
t1 = (n/p)*log2(n/p)
Определим трудоёмкость метода при слиянии массивов из процессов. Число итераций равно p-1, а в каждой итерации число перестановок равно отношению количества элементов в изначальном массиве n к используемуму количесву процессов на данной итерации. На первом шаге их p, на втором p/2 и т.д. То есть трудоёмкость t2 равна
t2 = n/p + 2*n/p + ... + n = n*(2p-1)/p
Общее время всех выполняемых в ходе сортировки операций передачи блоков можно оценить при помощи соотношения:
Tp(comm)=p(a+w(n/p)/b),
где a - латентность, b - пропускная способность сети передачи данных, w - размер элемента упорядочиваемых данных в байтах.
Окончательная оценка алгоритма Tp равна
Tp=Tp(comm)+t1+t2=p(a+w(n/p)/b) + (n/p)*log2(n/p) + n*(2p-1)/p
Общая оценка показателя ускорения равна:
Sp = n*log2n / [p(a+w(n/p)/b) + (n/p)*log2(n/p) + n*(2p-1)/p]
Оценка эффективности:
Ep = n*log2n / p*[p(a+w(n/p)/b) + (n/p)*log2(n/p) + n*(2p-1)/p]
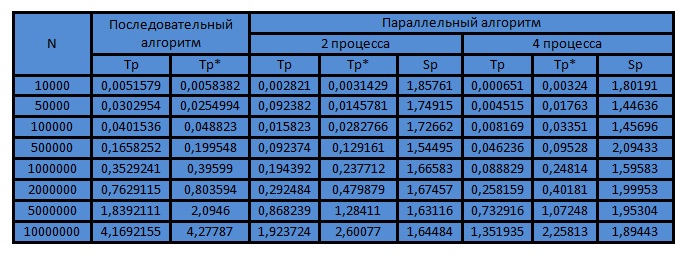
Результаты вычислительных экспериментов
Вычислительные эксперименты для оценки эффективности параллельного алгоритма сортировки слиянием проводились при следующих условиях и оборудовании:
- Процессор - Intel Core 2 Duo E6550, 2.33 ГГц
- Оперативная память - 4 GB
- Операционная система - Microsoft Windows 7 Enterprise
- Компилятор - MS Visual Studio 2008
- Длительность τ базовой скалярной операции - 14 нс
- Параметры передачи между процессами на одной машине: латентность α - 48,445 млс, пропускная способность β - 985123443 байт/c
- w = 4 байта
Об авторе
Работу выполнил студент группы 84-10 Мазур Е. С.



