Постановка задачи
1) Реализовать последовательный алгоритм перемножения матриц.
2) Реализовать программу блочного умножения матриц Фокса.
3) Рассчитать теоретическое ускорение и эффективность.
4) Провести набор тестов. Сравнить и сопоставить производительность трех
алгоритмов.
Описание
алгоритма и метод решения
Используется блочная схема разбиения матриц.При таком способе разделения
данных исходные матрицы А, В и результирующая матрица С представляются в виде
наборов блоков.Далее предполагается что все матрицы являются квадратными размера
n×n, количество блоков по горизонтали и вертикали одинаково и равно q (т.е.
размер всех блоков равен k×k, k=n/q). При таком представлении данных операция
матричного умножения матриц А и B в блочном виде может быть представлена
так:

За основу параллельных вычислений для матричного умножения при блочном
разделении данных принят подход, при котором базовые подзадачи отвечают за
вычисления отдельных блоков матрицы C и при этом в подзадачах на каждой итерации
расчетов располагается только по одному блоку исходных матриц A и B. Для
нумерации подзадач будем использовать индексы размещаемых в подзадачах блоков
матрицы C, т.е. подзадача (i,j) отвечает за вычисление блока Cij – тем самым,
набор подзадач образует квадратную решетку, соответствующую структуре блочного
представления матрицы C.
В соответствии с алгоритмом Фокса в ходе вычислений
на каждой базовой подзадаче (i,j) располагается четыре матричных
блока:
1.блок Cij матрицы C, вычисляемый подзадачей;
2.блок Aij
матрицы A, размещаемый в подзадаче перед началом вычислений;
3.блоки A'ij ,
B'ij матриц A и B, получаемые подзадачей в ходе выполнения
вычислений.
Выполнение параллельного метода включает:
1.этап
инициализации, на котором каждой подзадаче (i,j) передаются блоки Aij, Bij и
обнуляются блоки Cij на всех подзадачах;
2.этап вычислений, в рамках которого
на каждой итерации l, l от нуля(включительно) до q,осуществляются следующие
операции:
a.для каждой строки i(i от нуля включительно и строго до q) блок
Aij подзадачи (i,j) пересылается на все подзадачи той же строки i решетки;
индекс j, определяющий положение подзадачи в строке, вычисляется в соответствии
с выражением j=(i+l)mod q,где mod есть операция получения остатка от
целочисленного деления;
b.полученные в результаты пересылок блоки A'ij, B'ij
каждой подзадачи (i,j) перемножаются и прибавляются к блоку Cij
c.блоки B'ij каждой подзадачи (i,j) пересылаются
подзадачам, являющимся соседями сверху в столбцах решетки подзадач (блоки
подзадач из первой строки решетки пересылаются подзадачам последней строки
решетки).
Реализация алгоритма
// Для блочного разделения матрицы между процессами процессорной
решетки
void MatrixBlockScatter(double* pMatrix, double* pMatrixBlock,int
Size, int BlockSize) {
double * MatrixRow = new double
[BlockSize*Size];//буфер для временного хранения горизонтальной полосы матрицы
if (GridCoords[1] == 0) { //функцию Scatter вызываем только в тех процессах
которые расположены в нулевом столбце решетки
MPI_Scatter(pMatrix,
BlockSize*Size, MPI_DOUBLE, MatrixRow,BlockSize*Size, MPI_DOUBLE, 0, ColComm);
}
for (int i=0; i
MPI_Scatter(&MatrixRow[i*Size], BlockSize,
MPI_DOUBLE,&(pMatrixBlock[i*BlockSize]), BlockSize, MPI_DOUBLE, 0, RowComm);
}
delete [] MatrixRow;
}
//поблочно разделяем матрицу
А(блоки сохр-ся в переменной pMatrixABlock) и матрицу В(блоки сохр-ся в
переменной pBblock)
void MatrixBlockDistribution(double* pAMatrix, double*
pBMatrix, double* pMatrixAblock, double* pBblock, int Size, int BlockSize) {
// Поблочно разделяем матрицу А и В
MatrixBlockScatter(pAMatrix,
pMatrixAblock, Size, BlockSize);
MatrixBlockScatter(pBMatrix, pBblock, Size,
BlockSize);
}
// сбор результирующей матрицы С
void
GatherResultMatrix(double* pCMatrix, double* pCblock, int Size,int BlockSize) {
double * pResultRow = new double [Size*BlockSize];
for (int i=0;
i MPI_Gather( &pCblock[i*BlockSize], BlockSize,
MPI_DOUBLE,&pResultRow[i*Size], BlockSize, MPI_DOUBLE, 0, RowComm);
}
if (GridCoords[1] == 0) {
MPI_Gather(pResultRow, BlockSize*Size,
MPI_DOUBLE, pCMatrix,BlockSize*Size, MPI_DOUBLE, 0, ColComm);
}
delete
[] pResultRow;
}
// Рассылка блоков матрицы А по всем процессам
своей строки решетки
void ABlockBroadCastRow(int iteration, double *pAblock,
double* pMatrixAblock,int BlockSize) {
//определяем процесс который будет
рассылать свой блок матрицы А по всем процессам своей строки решетки
int
UseRowProc = (GridCoords[0] + iteration) % GridSize;// GridCoords[0]-номер
строки процессной решетки,для которой определяется номер рассылающего процесса
//копирование блока pMatrixAblock в буфер pAblock
if (GridCoords[1] ==
UseRowProc) {
for (int i=0; i pAblock[i] =
pMatrixAblock[i];
}
//,затем буфер pAblock рассылается на все
процессы(широковещательная рассылка)
MPI_Bcast(pAblock, BlockSize*BlockSize,
MPI_DOUBLE, UseRowProc, RowComm);
}
//Циклический сдвиг блоков
матрицы В вдоль столбцов процессорной решетки
void
BblockDataInterchangeColumn(double *pBblock, int BlockSize) {
MPI_Status
Status;
int NextProc = GridCoords[0] + 1;
if ( GridCoords[0] ==
GridSize-1 ) NextProc = 0;
int PrevProc = GridCoords[0] - 1;
if (
GridCoords[0] == 0 ) PrevProc = GridSize-1;
MPI_Sendrecv_replace( pBblock,
BlockSize*BlockSize, MPI_DOUBLE,PrevProc, 0, NextProc, 0, ColComm, &Status);
}
//Код,выполняющий алгоритм Фокса матричного умножения
//для выполнения матричного умножения с помощью данного алгоритма необходимо
выполнить GridSize итераций,каждая из которых состоит из трех действий
void
ParallelAlgorithmFox(double* pAblock, double* pMatrixAblock, double* pBblock,
double* pCblock, int BlockSize) {
for (int iteration = 0; iteration <
GridSize; iteration ++) {
// Рассылка блоков матрицы А по всем процессам
своей строки решетки
ABlockBroadCastRow (iteration, pAblock, pMatrixAblock,
BlockSize);
//Умножение матричных блоков на каждом процессе
MatrixBlockMultiplication(pAblock, pBblock, pCblock, BlockSize);
//Циклический сдвиг блоков матрицы В вдоль столбцов процессорной решетки
BblockDataInterchangeColumn(pBblock, BlockSize);
}
}
Анализ эффективности
Все матрицы являются квадратными размера n×n, количество блоков по
горизонтали и вертикали являются одинаковым и равным q (т.е. размер всех блоков
равен k×k, k=n/q), процессоры образуют квадратную решетку и их количество равно
p=q^2
Алгоритм Фокса требует для своего выполнения q итераций, в ходе которых
каждый процессор перемножает свои текущие блоки матриц А и В и прибавляет
результаты умножения к текущему значению блока матрицы C. С учетом выдвинутых
предположений общее количество выполняемых при этом операций будет иметь порядок
n3/p. Как результат, показатели ускорения и эффективности алгоритма имеют
вид:

Общий анализ сложности дает идеальные показатели эффективности параллельных
вычислений. Уточним полученные соотношения — для этого укажем более точно
количество вычислительных операций алгоритма и учтем затраты на выполнение
операций передачи данных между процессорами.
Определим количество
вычислительных операций. Сложность выполнения скалярного умножения строки блока
матрицы A на столбец блока матрицы В можно оценить как 2(n/q)-1. Количество
строк и столбцов в блоках равно n/q и, как результат, трудоемкость операции
блочного умножения оказывается равной (n2/p)(2n/q-1). Для сложения блоков
требуется n2/p операций. С учетом всех перечисленных выражений время выполнения
вычислительных операций алгоритма Фокса может быть оценено следующим
образом:
Общий анализ сложности дает идеальные показатели эффективности параллельных
вычислений. Уточним полученные соотношения — для этого укажем более точно
количество вычислительных операций алгоритма и учтем затраты на выполнение
операций передачи данных между процессорами.
Определим количество
вычислительных операций. Сложность выполнения скалярного умножения строки блока
матрицы A на столбец блока матрицы В можно оценить как 2(n/q)-1. Количество
строк и столбцов в блоках равно n/q и, как результат, трудоемкость операции
блочного умножения оказывается равной (n2/p)(2n/q-1). Для сложения блоков
требуется n2/p операций. С учетом всех перечисленных выражений время выполнения
вычислительных операций алгоритма Фокса может быть оценено следующим
образом:

Примечание: τ есть время выполнения одной элементарной скалярной
операции.
Общее время выполнения алгоритма Фокса может быть определено
при помощи следующих соотношений:

Примечание:Параметр q определяет
размер процессорной решетки и q=sqrt(p)
Демонстрация
Демонстрацию работы Fox's алгоритма рассмотрим на примере
умножения двух квадратных матриц 6 порядка на 9
процессорах. Пусть А и В - произвольные квадратные матрицы
6 порядка:
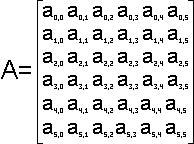
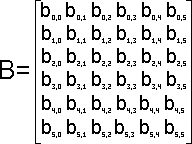
В процессе перемножения матриц
A и В каждый процессор будет работать с подматрицами 2
порядка Ai,j и
Bi,j исходных матриц:
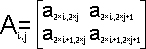
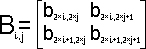 Пошаговая демонстрация работы алгоритма
Пошаговая демонстрация работы алгоритма
Результаты вычислительных экспериментов
Эксперименты проводились на двухпроцессорном вычислительном
узле на базе двухядерного процессора Intel Core i3 350M with Hyper Threding
, 2.26 ГГц, 3 Гб RAM, под управлением операционной системы Microsoft
Windows 7 Home Basic. Разработка программ проводилась в среде Microsoft Visual
Studio 2008, для компиляции использовался стандартный компилятор,
предоставляемый средой, с включенной полной оптимизацией.
| Размер матрицы |
Последовательный алгоритм |
Паралельный алгоритм (4 процесса) |
Паралельный алгоритм (теор. время) |
Ускорение |
| 100 |
0.019246 |
0.0186685 |
0.01854 |
1.030934 |
| 300 |
0.357236 |
0.224743 |
0.08751 |
1.589531 |
| 400 |
0.91644 |
0.425568 |
0.17432 |
2.153451 |
| 600 |
3.842139 |
1.585127 |
0.69576 |
2.423868 |
| 800 |
10.095123 |
3.973127 |
0.82451 |
2.540851 |
| 1000 |
19.259813 |
7.291964 |
2,95708 |
2.641238 |
| 2000 |
180.704049 |
67.315426 |
37,00741 |
2.809653 |
| 3000 |
632.003455 |
198.299785 |
103,4576 |
3.186934 |
| 4000 |
2053.71872 |
618.439123 |
255.3056 |
3,32432 |
Эксперименты показали, что
Латентность: a = 0,000022 cек
Скорость обмена между процессами - 872368616
байт/c
Время выполнения базовой операции перестановки - 10 нс
Размер
элемента набора - 8 байт (double)
Автор: Громов А.Д. группа 84-10



