Постановка задачи
Массивы это часто используемый элемент в программе. И самая распространенная операция, выполняемая над ними, это операция сортировки, заключающаяся в том, чтобы последовательность a0, a1... an расположить в таком порядке, когда выполняется условие: ai <= ai+1, для всех i от 0 до n.
Существует множество различных алгоритмов сортировки, но самый простой из них это сортировка пузырьком. К сожалению, он также один из самых медленных. Избавиться от этого недостатка помогает алгоритм параллельной пузырьковой сортировки, который мы и ставим целью реализовать.
Метод решения
Для реализации поставленной задачи потребуется модифицированный алгоритм последовательной пузырьковой сортировки под названием «чет-нечет». Смысл его заключается в том, что элементы сравниваются по другому правилу, в отличие от обычного «пузырька», где это происходит последовательно от первой пары элементов, до последней. В модификации с последующим элементом на четных итерациях сравниваются и, если надо, меняются местами четные элементы, а на нечетных соответственно нечетные элементы. Например на 2 итерации будут сравниваться такие пары:(a0, a1)( a2, a3)( a4, a5)…( an,an+1)(åñëè n ÷åòíî), а на 3 следующие: (a1, a2)(a3,a4)(a5,a6)…(an+1,an+2).И после n таких сравнений и перестановок мы получим отсортированный массив.
Алгоритм решения
Приведенный выше модифицированный алгоритм легко расспаралелить.
- Делим массив из n элементов на количество процессов p.
- Отсылаем каждому процессу его часть массива из n/p элементов.
- Каждый процесс сортирует полученную часть методом быстрой сортировки.
- Теперь в цикле от 1 до p выполняем следующие действия для каждого процесса:
- Если номер итерации четный и номер процесса четный или номер итерации нечетный и номер процесса нечетный, тогда посылаем и принимаем массив от предыдущего процесса.
- Склеиваем полученный массив с массивом процесса, который его получил, сохраняя упорядоченность.
- Из полученного массива запоминаем p/n больших элементов.
- Если номер итерации четный и номер процесса нечетный или номер итерации нечетный и номер процесса четный, тогда посылаем и принимаем массив от следующего процесса.
- Склеиваем полученный массив с массивом процесса, который его получил, сохраняя упорядоченность.
- Из полученного массива запоминаем p/n меньших элементов.
- 5 Склеиваем части со всех процессов в один отсортированный массив.
Анализ эффективности
На начальной стадии работы метода каждый процесс проводит сортировку своей части массива (размер части при равномерном распределении данных равен n/p). Данная начальная сортировка выполняется при помощи быстродействующих алгоритмов упорядочивания данных (алгоритма быстрой сортировки), тогда трудоемкость начальной стадии вычислений можно определить выражением вида:
T1p=(n/p)log2(n/p)
Далее, на каждой выполняемой итерации параллельной сортировки, взаимодействующие пары процессоров осуществляют передачу блоков между собой, после чего получаемые на каждом процессоре пары блоков объединяются при помощи процедуры слияния. Общее количество итераций не превышает величины p, и, как результат, общее количество операций этой части параллельных вычислений оказывается равным:
T2p=2p(n/p)=2n
Следует также учесть трудоемкость коммуникационных действий:
Tp(comm)=p(a+w(n/p)b)
Где а – латентность, b - пропускная способность сети передачи данных, w - размер элемента упорядочиваемых данных в байтах.
Общее время выполнения:
Tp=((n/p)log2(n/p)+2n)t+ p(a+w(n/p)b)
Где t - время выполнения базовой операции сортировки.
Ускорение S и эффективность E мы можем найти следующим образом:
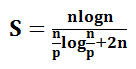
![]()
Демонстрация работы
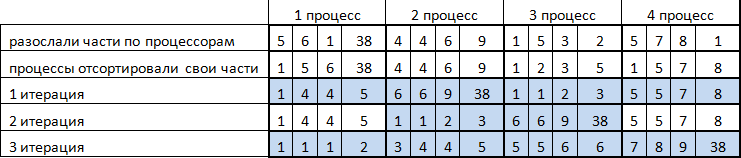
Результаты вычислительных экспериментов
![]()




