· Необходимо выполнить реализацию
параллельного алгоритма Прима.
· Необходимо провести вычислительные
эксперименты.
· Необходимо построить теоретические оценки с
учетом параметров используемой вычислительной системы.
· Сравнить полученные оценки с
экспериментальными данными.
Теоретическая часть
Каркас неориентированного графа
Оптимальным каркасом взвешенного графа называется каркас, минимизирующий
некоторую функцию от весов входящих в него ребер. Чаще всего в качестве такой
функции выступает сумма весов ребер, реже — произведение. Оптимальный каркас
еще называют кратчайшей связывающей сетью для данного графа. Задача о
построении кратчайшей связывающей сети встречается в различных приложениях
достаточно часто.
Задача об оптимальном каркасе.
Задача об оптимальном каркасе (стягивающем дереве) состоит в следующем. Дан
обыкновенный граф G=(V,E) и весовая функция на множестве ребер u: V R. Вес
множества X E определяется как
сумма весов составляющих его ребер. Требуется в графе G найти каркас
минимального веса. В этом разделе будем предполагать, что граф G связен, так
что решением задачи всегда будет дерево. Для решения задачи об оптимальном
каркасе известно несколько алгоритмов. Рассмотрим два из них.
Алгоритм Прима.
Этот алгоритм назван в честь американского математика Роберта Прима (Robert
Prim), который открыл этот алгоритм в 1957 г. Впрочем, ещё в 1930 г. этот
алгоритм был открыт чешским математиком Войтеком Ярником (Vojtěch
Jarník). Кроме того, Эдгар Дейкстра (Edsger Dijkstra) в 1959 г. также
изобрёл этот алгоритм, независимо от них.
Описание алгоритма
Искомый минимальный остов строится постепенно, добавлением в него рёбер по
одному. Изначально остов полагается состоящим из единственной вершины (её можно
выбрать произвольно). Затем выбирается ребро минимального веса, исходящее из
этой вершины, и добавляется в минимальный остов. После этого остов содержит уже
две вершины, и теперь ищется и добавляется ребро минимального веса, имеющее
один конец в одной из двух выбранных вершин, а другой — наоборот, во всех
остальных, кроме этих двух. И так далее, т.е. всякий раз ищется минимальное по
весу ребро, один конец которого — уже взятая в остов вершина, а другой конец —
ещё не взятая, и это ребро добавляется в остов (если таких рёбер несколько,
можно взять любое). Этот процесс повторяется до тех пор, пока остов не станет
содержать все вершины (или, что то же самое, ребро).
В итоге будет построен остов, являющийся минимальным. Если граф был
изначально не связен, то остов найден не будет (количество выбранных рёбер
останется меньше ).
Общее описание схемы программной
разработки
Пусть граф состоит из N вершин, ПОКА в каркасе не будет N
вершин
{
Каждому процессу выделяются
блоки матрицы.
На этих блоках каждый из
процесс ищет минимальное по весу ребро, соединяющее некаркасную вершину с
каркасной.
Каждый процесс отправляет
результат первому процессу.
Первый процесс ищет минимум
среди всех полученных ребер и результат отправляет всем остальным
процессам.
}
Параллельный код программы
void
InitMas(int** p,int N)
{
int
Max=1000;
int* Nodes=new int[N];
int Count=1;
for(int
i=0;i
Nodes[i]=0;
Nodes[0]=1;
for(int k=1;k
{
int y=rand()%(N-Count);
for(int i=1;i
if(Nodes[i]==0)
if(y==0)
{
y=rand()%(Count);
for(int j=0;j
if(Nodes[j]==1)
{
if(y==0)
{
p[j][i]=rand()%(Max)+1;
p[i][j]=p[j][i];
}
else y--;
Nodes[i]=1;
Count++;
}
}
else y--;
}
for(int i=0;i
for(int
j=i;j
if(i==j)
p[j][i]=p[i][j]=0;
else
if(!((p[i][j]>0)&&(p[i][j]<=Max)))
{
p[i][j]=rand()%(Max+1);
p[j][i]=p[i][j];
}
delete Nodes;
}
void
main(int argc, char *argv[])
{
int n;
int minonstep;
int **graph;
int **result;
int* used;
double start;
int rank, size;
float h;
int Max=1000;
MPI_Init(&argc, &argv);
MPI_Status status;
MPI_Comm_rank(MPI_COMM_WORLD,
&rank);
MPI_Comm_size(MPI_COMM_WORLD,
&size);
if(rank==0)
{
cout<<"Input
number of nodes";
cout<<"\n";
cin>>n;
}
MPI_Bcast(&n,
1, MPI_INT, 0, MPI_COMM_WORLD);
graph = new int* [n];
for( int i = 0; i < n; i++)
graph[i] = new int [n];
if(rank==0)
{
result = new int* [n];
for( int i = 0; i < n; i++)
result[i] =
new int [n];
for(int i=0;i
for (int j=0;j
result[i][j]=0;
InitMas(graph,n);
}
for(int i=0;i
MPI_Bcast(graph[i], n, MPI_INT, 0,
MPI_COMM_WORLD);
MPI_Bcast(&Max, 1, MPI_INT, 0,
MPI_COMM_WORLD);
used=new int[n];
used[0]=1;
for(int i=1;i
used[i]=0;
h = n /(float)size;
int y=1;
int position = 0;
int p[3];
MPI_Barrier(MPI_COMM_WORLD);
start
= MPI_Wtime();
for(int k=1;k
{
p[2]=Max+1;
for (int i = ceil(rank *
h); i < (rank + 1) * h; i++)
Общий анализ сложности параллельного алгоритма Прима для нахождения минимального охватывающего дерева
дает идеальные показатели эффективности параллельных вычислений:
При выполнении вычислений на отдельной итерации параллельного алгоритма Прима
каждый процессор определяет номер ближайшей вершины из своего блока до
охватывающего дерева. Этот поиск производиться самым безхитростным образом, то
есть просматриваются все пары вершин (x,y) c x принадлежащему каркасу, а у
остальному графу. Если в каркасе "k" вершин то до промотреть (n-k)
ребер. Причем это делается для n/p вершинах Как результат, с учетом общего
количества итераций n время выполнения вычислительных операций параллельного
алгоритма Прима может быть оценено при помощи соотношения:
Операция сбора данных от всех процессоров на одном из процессоров может быть
произведена за O(log2p) итераций, при этом общая оценка длительности выполнения
передачи данных определяется выражением:
где – латентность сети
передачи данных – пропускная способность сети, а - есть размер одного пересылаемого элемента данных в байтах
(коэффициент 3 в выражении соответствует числу передаваемых значений между
процессорами – длина минимальной дуги и номера двух вершин, которые соединяются
этой дугой).
Коммуникационная операция передачи данных от одного процессора всем процессорам
вычислительной системы также может быть выполнена за О(log2p) итераций при
общей оценке времени выполнения вида:
С учетом всех полученных соотношений общее время выполнения параллельного
алгоритма Прима составляет:
Результаты
Эксперимент проводился на ПК со следующими характеристиками:
Intel Core 2 Duo, 2.33 MHz
Microsoft Windows 7
Компилятор MS Visual Studio 2005
Пропускной способности сети - 36 Мбайт/с.
величина =4 байтам. = 2.4 нсек
Латентность: 0.00015 с




 E определяется как
сумма весов составляющих его ребер. Требуется в графе G найти каркас
минимального веса. В этом разделе будем предполагать, что граф G связен, так
что решением задачи всегда будет дерево. Для решения задачи об оптимальном
каркасе известно несколько алгоритмов. Рассмотрим два из них.
E определяется как
сумма весов составляющих его ребер. Требуется в графе G найти каркас
минимального веса. В этом разделе будем предполагать, что граф G связен, так
что решением задачи всегда будет дерево. Для решения задачи об оптимальном
каркасе известно несколько алгоритмов. Рассмотрим два из них.  ребро).
ребро).



 латентность сети
передачи данных
латентность сети
передачи данных  – пропускная способность сети, а
– пропускная способность сети, а  - есть размер одного пересылаемого элемента данных в байтах
(коэффициент 3 в выражении соответствует числу передаваемых значений между
процессорами – длина минимальной дуги и номера двух вершин, которые соединяются
этой дугой).
- есть размер одного пересылаемого элемента данных в байтах
(коэффициент 3 в выражении соответствует числу передаваемых значений между
процессорами – длина минимальной дуги и номера двух вершин, которые соединяются
этой дугой). 
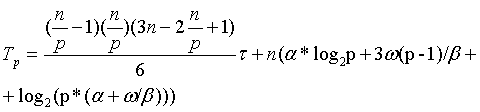
 =4 байтам.
=4 байтам.  = 2.4 нсек
= 2.4 нсек 