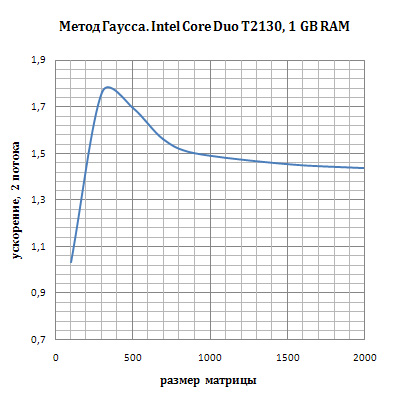
Вид данного графика объясняется особенностями архитектуры процессора Intel
Core Duo T2130. Рост ускорения при размере матрицы n < = 350 связан с
относительным уменьшением накладных расходов на переключение контекста
выполнения между потоками по сравнению с общим увеличением времени на проведение
вычислений. Наличие максимума на графике объясняется тем, что при n = 350
обрабатываемая матрица еще целиком убирается в в L2 кэш процессора, размер
которого равен 1 Mb. Приn > 350 мы видим уменьшение ускорения, т.к.
матрица цже целиком не убирается в L2 кэш и при данной схеме реализации
параллельного алгоритма при обращении каждого потока к своей части
матрицы происходит сброс содержимого кэша (напомним, что каждый поток
обрабатывает свою полосу матрицы). Т.о. накладные расходы по обращению к L2 кэш
памяти процессора сводят на нет эффект от параллельной схемы вычислений, но тем
не менее ускорение все же наблюдается.



