Постановка задачи.
Задача сортировки является одной из основных при
написании практически любой программы. С данными, представляющими собой
упорядоченный определенным образом массив, значительно удобнее работать как
компьютеру, так и человеку. Для того чтобы ускорить процесс сортировки массива,
используются различные параллельные методы, что увеличивает эффективность и
скорость работы программы.
В данной лабораторной работе рассматривается алгоритм
сортировки «пузырьком» и его параллельная модификация (чет-нечетная
перестановка). Описание последовательного метода.
Последовательный алгоритм пузырьковой сортировки сравнивает и обменивает
соседние элементы в последовательности, которую нужно
отсортировать. Для последовательности (a1, a2, ..., an) алгоритм сначала выполняет n-1 базовых операций
"сравнения-обмена" для последовательных пар элементов (a1, a2), (a2, a3), ..., (an-1, an). В результате после первой итерации алгоритма самый большой
элемент перемещается ("всплывает") в конец последовательности.
Далее последний элемент в преобразованной последовательности
может быть исключен из рассмотрения, и описанная выше процедура
применяется к оставшейся части последовательности (a'1, a'2, ..., a'n-1). Как можно увидеть, последовательность будет отсортирована
после n-1 итерации. Параллельная схема.
Алгоритм пузырьковой сортировки в прямом виде достаточно
сложен для распараллеливания – сравнение пар значений
упорядочиваемого набора данных происходит строго последовательно.
В связи с этим для параллельного применения используется не сам
этот алгоритм, а его модификация. Суть модификации состоит в том,
что в алгоритм сортировки вводятся два разных правила выполнения
итераций метода: в зависимости от четности или нечетности номера
итерации сортировки для обработки выбираются элементы с четными
или нечетными индексами соответственно, сравнение выделяемых
значений всегда осуществляется с их правыми соседними элементами.
Таким образом, на всех нечетных итерациях сравниваются пары (a1, a2), (a3, a4), ..., (an-1,an), а на четных итерациях обрабатываются элементы (a2, a3), (a4, a5), ..., (an-2,an-1). После n -кратного повторения итераций сортировки
исходный набор данных оказывается упорядоченным.
Пусть нам дан неупорядоченный массив из n элементов и p процессов. Разделим данный массив на p равных частей и каждому процессу выдадим соответствующий блок. Каждый процесс сортирует свой массив "пузырьком". Далее происходит чередование чет-нечетных перестановок на p итерациях. После этого части массивов отсылаются на главный процесс и там объединяются, таким образом получается отсортированный массив. Анализ эффективности.
Определим теперь сложность рассмотренного параллельного алгоритма упорядочивания данных. Как отмечалось ранее, на начальной стадии работы метода каждый процессор проводит упорядочивание своих блоков данных (размер блоков при равномерном распределении данных является равным n/p). Трудоемкость начальной стадии вычислений можно определить выражением вида:
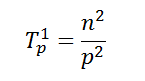
Далее, на каждой выполняемой итерации параллельной сортировки взаимодействующие пары процессоров осуществляют передачу блоков между собой, после чего получаемые на каждом процессоре пары блоков объединяются при помощи процедуры слияния. Общее количество итераций не превышает величины p, и, как результат, общее количество операций этой части параллельных вычислений оказывается равным:
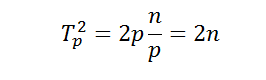
С учетом полученных соотношений показатели эффективности и ускорения параллельного метода сортировки имеют вид:
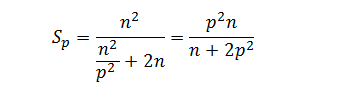
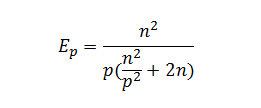
Расширим приведенные выражения – учтем длительность выполняемых вычислительных операций и оценим трудоемкость операции передачи блоков между процессорами. При использовании модели Хокни общее время всех выполняемых в ходе сортировки операций передачи блоков можно оценить при помощи соотношения вида:
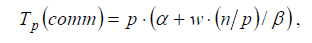
где α – латентность, β – пропускная способность сети передачи данных, а w есть размер элемента упорядочиваемых данных в байтах.
С учетом трудоемкости коммуникационных действий общее время выполнения параллельного алгоритма сортировки определяется следующим выражением: 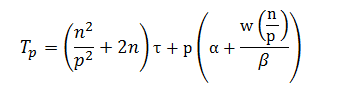
где τ есть время выполнения базовой операции сортировки. Демонстрация.
Результаты вычислительных экспериментов.

CPU: Intel(R) Core(TM)2 Duo CPU P8400 @ 2.26GHz
RAM : 2 GB DDR2
Cores: 2
L1 Cache: 64 KBytes
L2 Cache: 3 MBytes
Операционная система - MS Windows 7 x32
Компилятор - MS Visual Studio 2008 Об авторе.
Работу выполнил студент группы 8409 Кутилов Егор
| 


