.gif) – 1)) / 2û
– 1)) / 2ûКак уже отмечалось ранее, временные задержки при передаче данных по каналам связи для организации взаимодействия раздельно-функционирующих процессов могут в значительной степени определять эффективность параллельных вычислений. Данный раздел посвящен вопросам анализа информационных потоков, возникающих при выполнении параллельных алгоритмов. В разделе определяются показатели, характеризующие свойства топологий коммуникационных сетей, дается общая характеристика механизмов передачи данных, проводится анализ трудоемкости основных операций обмена информацией, рассматриваются методы логического представления структуры МВС. Более подробно изучаемый в данном разделе пособия учебный материал излагается в [18, 23, 28].
В качестве основных характеристик топологии сети передачи данных наиболее широко используется следующий ряд показателей:
Для сравнения в таблице 3.1 приводятся значения перечисленных показателей для различных топологий сети передачи данных.
Таблица 3.1. Характеристики топологий сети передачи данных (p - количество процессоров)
| Топология | Диаметр | Ширина бисекции | Связность | Стоимость |
|---|---|---|---|---|
| Полный граф | 1 | p2 / 4 | p – 1 | p (p – 1) / 2 |
| Звезда | 2 | 1 | 1 | p – 1 |
| Полное двоичное дерево | 2 log ((p + 1) / 2) | 1 | 1 | p – 1 |
| Линейка | p – 1 | 1 | 1 | p – 1 |
| Кольцо | ëp / 2û | 2 | 2 | p |
| Решетка (N = 2) | 2( – 1) |
| 2 | 2 (p – ) |
| Решетка-тор (N = 2) | 2ë / 2û |
2 |
4 | 2p |
| Гиперкуб | log p | p / 2 | log p | (p log p) / 2 |
Алгоритмы маршрутизации определяют путь передачи данных от процессора-источника сообщения до процессора, к которому сообщение должно быть доставлено. Среди возможных способов решения данной задачи различают:
К числу наиболее распространенных оптимальных алгоритмов относится класс методов покоординатной маршрутизации (dimension-ordered routing), в которых поиск путей передачи данных осуществляется поочередно для каждой размерности топологии сети коммуникации. Так, для двумерной решетки такой подход приводит к маршрутизации, при которой передача данных сначала выполняется по одному направлению (например, по горизонтали до достижения вертикали процессоров, в которой располагается процессор назначения), а затем данные передаются вдоль другого направления (данная схема известна под названием алгоритма XY-маршрутизации).
Для гиперкуба покоординатная схема маршрутизации может состоять, например, в циклической передаче данных процессору, определяемому первой различающейся битовой позицией в номерах процессоров, на котором сообщение располагается в данный момент времени и на который сообщение должно быть передано.
Время передачи данных между процессорами определяет коммуникационную составляющую (communication latency) длительности выполнения параллельного алгоритма в многопроцессорной вычислительной системе. Основной набор параметров, описывающих время передачи данных, состоит из следующего ряда величин:
К числу наиболее распространенных методов передачи данных относятся следующие два основные способа коммуникации [23]. Первый из них ориентирован на передачу сообщений (МПС) как неделимых (атомарных) блоков информации (store-and-forward routing or SFR). При таком подходе процессор, содержащий сообщение для передачи, готовит весь объем данных для передачи, определяет процессор, которому следует направить данные, и запускает операцию пересылки данных. Процессор, которому направлено сообщение, в первую очередь осуществляет прием полностью всех пересылаемых данных и только затем приступает к пересылке принятого сообщения далее по маршруту. Время пересылки данных tпд для метода передачи сообщения размером m по маршруту длиной l определяется выражением
tпд = tн + (mtк + tс)l .
При достаточно длинных сообщениях временем передачи служебных данных можно пренебречь и выражение для времени передачи данных может быть записано в более простом виде
tпд = tн + mtкl .
Второй способ коммуникации основывается на представлении пересылаемых сообщений в виде блоков информации меньшего размера (пакетов), в результате чего передача данных может быть сведена к передаче пакетов (МПП). При таком методе коммуникации (cut-through routing or CTR) принимающий процессор может осуществлять пересылку данных по дальнейшему маршруту непосредственно сразу после приема очередного пакета, не дожидаясь завершения приема данных всего сообщения. Время пересылки данных при использовании метода передачи пакетов будет определяться выражением
tпд = tн + mtк + tсl .
Сравнивая полученные выражения, можно заметить, что в большинстве случаев метод передачи пакетов приводит к более быстрой пересылке данных; кроме того, данный подход снижает потребность в памяти для хранения пересылаемых данных для организации приема-передачи сообщений, а для передачи пакетов могут использоваться одновременно разные коммуникационные каналы. С другой стороны, реализация пакетного метода требует разработки более сложного аппаратного и программного обеспечения сети, может увечить накладные расходы (время подготовки и время передачи служебных данных); при передаче пакетов возможно возникновения конфликтных ситуаций (дедлоков).
При всем разнообразии выполняемых операций передачи данных при параллельных способах решения сложных научно-технических задач определенные процедуры взаимодействия процессоров сети могут быть отнесены к числу основных коммуникационных действий, которые или наиболее широко распространены в практике параллельных вычислений, или к которым могут быть сведены многие другие процессы приема-передачи сообщений. Важно отметить также, что в рамках подобного базового набора для большинства операций коммуникации существуют процедуры, обратные по действию исходным операциям (так, например, операции передачи данных от одного процессора всем имеющимся процессорам сети соответствует операция приема в одном процессоре сообщений от всех остальных процессоров). Как результат, рассмотрение коммуникационных процедур целесообразно выполнять попарно, поскольку во многих случаях алгоритмы выполнения прямой и обратной операций могут быть получены исходя из общих положений.
Рассмотрение основных операций передачи данных в данном разделе будет осуществляться на примере таких топологий сети, как кольцо, двумерной решетки и гиперкуба. Для двумерной решетки будет предполагаться также, что между граничными процессорами в строках и столбцах решетки имеются каналы передачи данных (т.е. топология сети представляет из себя тор). Как и ранее, величина m будет означать размер сообщения в словах, значение p определяет количество процессоров в сети, а переменная N задает размерность топологии гиперкуба.
Трудоемкость данной коммуникационной операции может быть получена путем подстановки длины максимального пути (диаметра сети - см. табл. 3.1) в выражения для времени передачи данных при разных методах коммуникации (см. п. 3.2).
Таблица 3.2. Время передачи данных между двумя процессорами
| Топология | Передача сообщений | Передача пакетов |
|---|---|---|
| Кольцо | tн + mtкëp / 2û | tн + mtк + tсëp / 2û |
| Решетка-тор | tн + 2mtкë / 2û |
tн + mtк + 2tсë / 2û |
| Гиперкуб | tн + mtк log p | tн + mtк + tс log p |
Операция передачи данных (одного и того же сообщения) от одного процессора всем остальным процессорам сети (one-to-all broadcast or single-node broadcast) является одним из наиболее часто выполняемых коммуникационных действий; двойственная операция передачи - прием на одном процессоре сообщений от всех остальных процессоров сети (single-node accumulation). Подобные операции используются, в частности, при реализации матрично-векторного произведения, решении систем линейных уравнений при помощи метода Гаусса, поиска кратчайших путей и др.
Простейший способ реализации операции рассылки состоит в ее выполнении как последовательности попарных взаимодействий процессоров сети. Однако при таком подходе большая часть пересылок является избыточной и возможно применение более эффективных алгоритмов коммуникации. Изложение материала будет проводиться сначала для метода передачи сообщений, затем - для пакетного способа передачи данных (см. п. 3.2).
1. Передача сообщений. Для кольцевой топологии процессор-источник рассылки может инициировать передачу данных сразу двум своим соседям, которые, в свою очередь, приняв сообщение, организуют пересылку далее по кольцу. Трудоемкость выполнения операции рассылки в этом случае будет определяться соотношением
tпд = (tн + mtк)ép / 2ù .
Для топологии типа решетки-тора алгоритм рассылки может быть получен из способа передачи данных, примененного для кольцевой структуры сети. Так, рассылка может быть выполнена в виде двухэтапной процедуры. На первом этапе организуется передача сообщения всем процессорам сети, располагающимся на той же горизонтали решетки, что и процессор-инициатор передачи; на втором этапе процессоры, получившие копию данных на первом этапе, рассылают сообщения по своим соответствующим вертикалям. Оценка длительности операции рассылки в соответствии с описанным алгоритмом определяется соотношением
tпд = 2(tн + mtк)é / 2ù .
Для гиперкуба рассылка может быть выполнена в ходе N-этапной процедуры передачи данных. На первом этапе процессор-источник сообщения передает данные одному из своих соседей (например, по первой размерности) - в результате после первого этапа имеется два процессора, имеющих копию пересылаемых данных (данный результат можно интерпретировать также как разбиение исходного гиперкуба на два таких одинаковых по размеру гиперкуба размерности N – 1, что каждый из них имеет копию исходного сообщения). На втором этапе два процессора, задействованные на первом этапе, пересылают сообщение своим соседям по второй размерности и т.д. В результате такой рассылки время операции оценивается при помощи выражения
tпд = (tн + mtк) log p .
Сравнивая полученные выражения для длительности выполнения операции рассылки, можно отметить, что наилучшие показатели имеет топология типа гиперкуба; более того, можно показать, что данный результат является наилучшим для выбранного способа коммуникации с помощью передачи сообщений.
2. Передача пакетов. Для топологии типа кольца алгоритм рассылки может быть получен путем логического представления кольцевой структуры сети в виде гиперкуба. В результате на этапе рассылки процессор-источник сообщения передает данные процессору, находящемуся на расстоянии p / 2 от исходного процессора. Далее, на втором этапе оба процессора, уже имеющие рассылаемые данные после первого этапа, передают сообщения процессорам, находящиеся на расстоянии p / 4 и т.д. Трудоемкость выполнения операции рассылки при таком методе передачи данных определяется соотношением
tпд = .gif) (tн + mtк + tс p / 2i) = (tн + mtк) log p + tс(p – 1)
(tн + mtк + tс p / 2i) = (tн + mtк) log p + tс(p – 1)
(как и ранее, при достаточно больших сообщениях, временем передачи служебных данных можно пренебречь).
Для топологии типа решетки-тора алгоритм рассылки может быть получен из способа передачи данных, примененного для кольцевой структуры сети, в соответствии с тем же способом обобщения, что и в случае использования метода передачи сообщений. Получаемый в результате такого обобщения алгоритм рассылки характеризуется следующим соотношением для оценки времени выполнения:
tпд = (tн + mtк) log p + 2tс( – 1) .
Для гиперкуба алгоритм рассылки (и, соответственно, временные оценки длительности выполнения) при передаче пакетов не отличается от варианта для метода передачи сообщений.
Операция передачи данных от всех процессоров всем процессорам сети (all-to-all broadcast or multinode broadcast) является естественным обобщением одиночной операции рассылки; двойственная операция передачи - прием сообщений на каждом процессоре от всех процессоров сети (multinode accumulation). Подобные операции широко используются, например, при реализации матричных вычислений.
Возможный способ реализации операции множественной рассылки состоит в выполнении соответствующего набора операций одиночной рассылки. Однако такой подход не является оптимальным для многих топологий сети, поскольку часть необходимых операций одиночной рассылки потенциально может быть выполнена параллельно. Как и ранее, учебный материал будет рассматриваться раздельно для разных методов передачи данных (см. п. 3.2).
1. Передача сообщений. Для кольцевой топологии каждый процессор может инициировать рассылку своего сообщения одновременно (в каком-либо выбранном направлении по кольцу). В любой момент времени каждый процессор выполняет прием и передачу данных; завершение операции множественной рассылки произойдет через (p – 1) цикл передачи данных. Длительность выполнения операции рассылки оценивается соотношением:
tпд = (tн + mtк)(p – 1) .
Для топологии типа решетки-тора множественная рассылка сообщений может быть выполнена при помощи алгоритма, получаемого обобщением способа передачи данных для кольцевой структуры сети. Схема обобщения состоит в следующем. На первом этапе организуется передача сообщений раздельно по всем процессорам сети, располагающимся на одних и тех же горизонталях решетки (в результате на каждом процессоре одной и той же горизонтали формируются укрупненные сообщения размера m, объединяющие все сообщения горизонтали). Время выполнения этапа
t'пд = (tн + mtк)( – 1) .
На втором этапе рассылка данных выполняется по процессорам сети, образующим вертикали решетки. Длительность этого этапа
t''пд = (tн + mtк)( – 1) .
Как результат, общая длительность операции рассылки определяется соотношением:
tпд = 2tн( – 1) + mtк(p – 1) .
Для гиперкуба алгоритм множественной рассылки сообщений может быть получен путем обобщения ранее описанного способа передачи данных для топологии типа решетки на размерность гиперкуба N. В результате такого обобщения схема коммуникации состоит в следующем. На каждом этапе i, 1 ≤ i ≤ N, выполнения алгоритма функционируют все процессоры сети, которые обмениваются своими данными со своими соседями по i размерности и формируют объединенные сообщения. Время операции рассылки может быть получено при помощи выражения
tпд = (tн + 2i-1mtк) = tн log p + mtк(p – 1)
2. Передача пакетов. Применение более эффективного для кольцевой структуры и топологии типа решетки-тора метода передачи данных не приводит к какому-либо улучшению времени выполнения операции множественной рассылки, поскольку обобщение алгоритмов выполнения операции одиночной рассылки на случай множественной рассылки приводит к перегрузке каналов передачи данных (т.е. к существованию ситуаций, когда в один и тот же момент времени для передачи по одной и той линии передачи имеется несколько ожидающих пересылки пакетов данных). Перегрузка каналов приводит к задержкам при пересылках данных, что и не позволяет проявиться всем преимуществам метода передачи пакетов.
Возможным широко распространенным примером операции множественной рассылки является задача редукции (reduction), определяемая в общем виде, как процедура выполнения той или иной обработки получаемых на каждом процессоре данных (в качестве примера такой задачи может быть рассмотрена проблема вычисления суммы значений, находящихся на разных процессорах, и рассылки полученной суммы по всем процессорам сети). Способы решения задачи редукции могут состоять в следующем:
tпд = (tн + tк) log p .
Другим типовым примером используемости операции множественной рассылки является задача нахождения частных сумм последовательности значений Si (в зарубежной литературе эта задача известна под названием prefix sum problem)
Sk = .gif) xi, 1 ≤ k ≤ p
xi, 1 ≤ k ≤ p
(будем предполагать, что количество значений совпадает с количеством процессоров, значение xi располагается на i процессоре и результат Sk должен получаться на процессоре с номером k).
Алгоритм решения данной задачи также может быть получен при помощи конкретизации общего способа выполнения множественной операции рассылки, когда процессор выполняет суммирование полученного значения (но только в том случае, если процессор-отправитель значения имеет меньший номер, чем процессор-получатель).
Общий случай передачи данных от одного процессора всем остальным процессорам сети состоит в том, что все рассылаемые сообщения являются различными (one-to-all personalized communication or single-node scatter). Двойственная операция передачи для данного типа взаимодействия процессоров - обобщенный прием сообщений (single-node gather) на одном процессоре от всех остальных процессоров сети (отличие данной операции от ранее рассмотренной процедуры сборки данных на одном процессоре (single-node accumulation) состоит в том, что обобщенная операция сборки не предполагает какого-либо взаимодействия сообщений (типа редукции) в процессе передачи данных).
Трудоемкость операции обобщенной рассылки сопоставима со сложностью выполнения процедуры множественной передачи данных. Процессор-инициатор рассылки посылает каждому процессору сети сообщение размера m и, тем самым, нижняя оценка длительности выполнения операции характеризуется величиной mtk(p – 1).
Проведем более подробный анализ трудоемкости обобщенной рассылки для случая топологии типа гиперкуб. Возможный способ выполнения операции состоит в следующем. Процессор-инициатор рассылки передает половину своих сообщений одному из своих соседей (например, по первой размерности) - в результате, исходный гиперкуб становится разделенным на два гиперкуба половинного размера, в каждом из которых содержится ровно половина исходных данных. Далее действия по рассылке сообщений могут быть повторены и общее количество повторений определяется исходной размерностью гиперкуба. Длительность операции обобщенной рассылки может быть охарактеризована соотношением:
tпд = tн log p + mtk(p – 1)
(как и отмечалась выше, трудоемкость операции совпадает с длительностью выполнения процедуры множественной рассылки).
Обобщенная передача данных от всех процессоров всем процессорам сети (total exchange) представляет собой наиболее общий случай коммуникационных действий. Необходимость в выполнении подобных операций возникает в параллельных алгоритмах быстрого преобразования Фурье, транспонирования матриц и др.
Выполним краткую характеристику возможных способов выполнения обобщенной множественной рассылки для разных методов передачи данных (см. п. 3.2).
1. Передача сообщений. Общая схема алгоритма для кольцевой топологии состоит в следующем. Каждый процессор производит передачу всех своих исходных сообщений своему соседу (в каком-либо выбранном направлении по кольцу). Далее процессоры осуществляют прием направленных к ним данных, затем среди принятой информации выбирают свои сообщения, после чего выполняет дальнейшую рассылку оставшейся части данных. Длительность выполнения подобного набора передач данных оценивается при помощи выражения:
tпд = (tн + ½ mptk)(p – 1)
Способ получения алгоритма рассылки данных для топологии типа решетки-тора является тем же самым, что и в случае рассмотрения других коммуникационных операций. На первом этапе организуется передача сообщений раздельно по всем процессорам сети, располагающимся на одних и тех же горизонталях решетки (каждому процессору по горизонтали передаются только те исходные сообщения, что должны быть направлены процессорам соответствующей вертикали решетки); после завершения этапа на каждом процессоре собираются p сообщений, предназначенных для рассылки по одной из вертикалей решетки. На втором этапе рассылка данных выполняется по процессорам сети, образующим вертикали решетки. Общая длительность всех операций рассылок определяется соотношением
tпд = 2(tн + mptk)( – 1)
Для гиперкуба алгоритм обобщенной множественной рассылки сообщений может быть получен путем обобщения способа выполнения операции для топологии типа решетки на размерность гиперкуба N. В результате такого обобщения схема коммуникации состоит в следующем. На каждом этапе i, 1 ≤ i ≤ N, выполнения алгоритма функционируют все процессоры сети, которые обмениваются своими данными со своими соседями по i размерности и формируют объединенные сообщения. При организации взаимодействия двух соседей канал связи между ними рассматривается как связующий элемент двух равных по размеру подгиперкубов исходного гиперкуба, и каждый процессор пары посылает другому процессору только те сообщения, что предназначены для процессоров соседнего подгиперкуба. Время операции рассылки может быть получено при помощи выражения:
tпд = (tн + ½ mptk) log p
(кроме затрат на пересылку, каждый процессор выполняет mp log p операций по сортировке своих сообщений перед обменом информацией со своими соседями).
2. Передача пакетов. Как и в случае множественной рассылки, применение метода передачи пакетов не приводит к улучшению временных характеристик для операции обобщенной множественной рассылки. Рассмотрим для примера более подробно выполнение данной коммуникационной операции для сети с топологией типа гиперкуб. В этом случае рассылка может быть выполнена за p – 1 последовательных итераций. На каждой итерации все процессоры разбиваются на взаимодействующие пары процессоров, причем это разбиение на пары может быть выполнено таким образом, чтобы передаваемые между разными парами сообщения не использовали одни и те же пути передачи данных. Как результат, общая длительность операции обобщенной рассылки может быть определена в соответствии с выражением:
tпд = (tн + mtk)(p – 1) + ½ tc p log p
Частный случай обобщенной множественной рассылки есть процедура перестановки (permutation), представляющая собой операцию перераспределения информации между процессорами сети, в которой каждый процессор передает сообщение некоторому определенному другому процессору сети. Конкретный вариант перестановки - циклический q-сдвиг (circular q-shift), при котором каждый процессор i, 1 ≤ i ≤ p, передает данные процессору с номером (i + q) mod p. Подобная операция сдвига используется, например, при организации матричных вычислений.
Поскольку выполнение циклического сдвига для кольцевой топологии может быть обеспечено при помощи простых алгоритмов передачи данных, рассмотрим возможные способы выполнения данной коммуникационной операции только для топологий решетки-тора и гиперкуба при разных методах передачи данных (см. п. 3.2).
1. Передача сообщений. Общая схема алгоритма циклического сдвига для топологии типа решетки-тора состоит в следующем. Пусть процессоры перенумерованы по строкам решетки от 0 до p – 1. На первом этапе организуется циклический сдвиг с шагом q mod по каждой строке в отдельности (если при реализации такого сдвига сообщения передаются через правые границы строк, то после выполнения каждой такой передачи необходимо осуществить компенсационный сдвиг вверх на 1 для процессоров первого столбца решетки). На втором этапе реализуется циклический сдвиг вверх с шагом ëq / û для каждого столбца решетки. Общая длительность всех операций рассылок определяется соотношением
tпд = (tн + mtk)(2ë / 2û + 1)
Для гиперкуба алгоритм циклического сдвига может быть получен путем логического представления топологии гиперкуба в виде кольцевой структуры. Для получения такого представления установим взаимно-однозначное соответствие между вершинами кольца и гиперкуба. Необходимое соответствие может быть получено, например, при помощи известного кода Грея, который можно использовать для определения процессоров гиперкуба, соответствующих конкретным вершинам кольца. Более подробное изложение механизма установки такого соответствия осуществляется в п. 3.4; для наглядности на рис. 3.1 приводится вид гиперкуба для размерности N = 3 с указанием для каждого процессора гиперкуба соответствующей вершины кольца. Положительным свойством выбора такого соответствия является тот факт, что для любых двух вершин в кольце, расстояние между которыми является равным l = 2i для некоторого значения i, путь между соответствующими вершинами в гиперкубе содержит только две линии связи (за исключением случая i = 0, когда путь в гиперкубе имеет единичную длину).
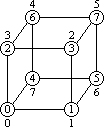
Рис. 3.1. Схема отображения гиперкуба на кольцо (в кружках приведены номера процессоров гиперкуба)
Представим величину сдвига q в виде двоичного кода. Количество ненулевых позиций кода определяет количество этапов в схеме реализации операции циклического сдвига. На каждом этапе выполняется операция сдвига с величиной шага, определяемой наиболее старшей ненулевой позицией значения q (например, при исходной величине сдвига q = 5 = 1012, на первом этапе выполняется сдвиг с шагом 4, на втором этапе шаг сдвига равен 1). Выполнение каждого этапа (кроме сдвига с шагом 1) состоит в передаче данных по пути, включающему две линии связи. Как результат, верхняя оценка для длительности выполнения операции циклического сдвига определяется соотношением:
tпд = (tн + mtk)(2 log p – 1)
2. Передача пакетов. Использование пересылки пакетов может повысить эффективность выполнения операции циклического сдвига для топологии гиперкуб. Реализация всех необходимых коммуникационных действий в этом случае может быть обеспечена путем отправления каждым процессором всех пересылаемых данных непосредственно процессорам назначения. Использование метода покоординатной маршрутизации (см. п. 3.2) позволит избежать коллизий при использовании линий передачи данных (в каждый момент времени для каждого канала будет существовать не более одного готового для отправки сообщения). Длина наибольшего пути при такой рассылке данных определяется как log p – γ(q), где γ(q) есть наибольшее целое значение j такое, что 2j есть делитель величины сдвига q. Тогда длительность операции циклического сдвига может быть определена при помощи выражения
tпд = tн + mtk + tс (log p – γ(q))
(при достаточно больших размерах сообщений временем передачи служебных данных можно пренебречь и время выполнения операции может быть определено как tпд = tн + mtk).
Как показало рассмотрение основных коммуникационных операций в п. 3.3, ряд алгоритмов передачи данных допускает более простое изложение при использовании вполне определенных топологий сети межпроцессорных соединений. Кроме того, многие методы коммуникации могут быть получены при помощи того или иного логического представления исследуемой топологии. Как результат, важным моментом является при организации параллельных вычислений умение логического представления разнообразных топологий на основе конкретных (физических) межпроцессорных структур.
Способы логического представления (отображения) топологий характеризуются следующими тремя основными характеристиками:
Для рассматриваемых в рамках пособия топологий ограничимся изложением вопросов отображения топологий кольца и решетки на гиперкуб; предлагаемые ниже подходы для логического представления топологий характеризуются единичными показателями уплотнения и удлинения дуг.
Установление соответствия между кольцевой топологией и гиперкубом может быть выполнено при помощи двоичного рефлексивного кода Грея G(i, N) (binary reflected Gray code),
| Код Грея для N = 1 | Код Грея для N = 2 | Код Грея для N = 3 | Номера процессоров | |
|---|---|---|---|---|
| гиперкуба | кольца | |||
| 0 | 0 0 | 0 0 0 | 0 | 0 |
| 1 | 0 1 | 0 0 1 | 1 | 1 |
| 1 1 | 0 1 1 | 3 | 2 | |
| 1 0 | 0 1 0 | 2 | 3 | |
| 1 1 0 | 6 | 4 | ||
| 1 1 1 | 7 | 5 | ||
| 1 0 1 | 5 | 6 | ||
| 1 0 0 | 4 | 7 | ||
Рис. 3.2. Отображение кольцевой топологии на гиперкуб при помощи кода Грея
определяемого в соответствии с выражениями:
G(0, 1) = 0, G(1, 1) = 1,
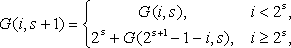
где i задает номер значения в коде Грея, а N есть длина этого кода. Для иллюстрации подхода на рис. 3.2 показывается отображение кольцевой топологии на гиперкуб для сети из p = 8 процессоров.
Важным свойством кода Грея является тот факт, что соседние значения G(i, N) и G(i + 1, N) имеют только одну различающуюся битовую позицию. Как результат, соседние вершины в кольцевой топологии отображаются на соседние процессоры в гиперкубе.
Отображение топологии решетки на гиперкуб может быть выполнено в рамках подхода, использованного для кольцевой структуры сети. Тогда для отображения решетки 2r×2s на гиперкуб размерности N = r + s можно принять правило, что элементу решетки с координатами (i, j), будет соответствовать процессор гиперкуба с номером
G(i, r) || G(j, s),
где операция || означает конкатенацию кодов Грея
Для кластерных вычислительных систем (см. п. 1.3) одним из широко применяемых способов построения коммуникационной среды является использование концентраторов (hub) или переключателей (switch) для объединения процессорных узлов кластера в единую вычислительную сеть. В этих случаях топология сети кластера представляет собой полный граф, в котором, однако, имеются определенные ограничения на одновременность выполнения коммуникационных операций. Так, при использовании концентраторов передача данных в каждый текущий момент времени может выполняться только между двумя процессорными узлами; переключатели могут обеспечивать взаимодействие нескольких непересекающихся пар процессоров.
Другое часто применяемое решение при создании кластеров состоит в использовании метода передачи пакетов (реализуемого, как правило, на основе протокола TCP/IP) в качестве основного способа выполнения коммуникационных операций.
1. Выбирая для дальнейшего анализа кластеры данного распространенного типа (топология в виде полного графа, пакетный способ передачи сообщений), трудоемкость операции коммуникации между двумя процессорными узлами может быть оценена в соответствии с выражением (модель А)
tпд(m) = tн + mtk + tс,
оценка подобного вида следует из соотношений для метода передачи пакетов при единичной длине пути передачи данных, т.е. при l = 1. Отмечая возможность подобного подхода, вместе с этим можно заметить, что в рамках рассматриваемой модели время подготовки данных tн предполагается постоянным (не зависящим от объема передаваемых данных), время передачи служебных данных tс не зависит от количества передаваемых пакетов и т.п. Эти предположения не в полной мере соответствуют действительности и временные оценки, получаемые в результате использования модели, могут не обладать необходимой точностью.
2. Учитывая все приведенные замечания, схема построения временных оценок может быть уточнена; в рамках новой расширенной модели трудоемкость передачи данных между двумя процессорами определяется в соответствии со следующими выражениями (модель В):
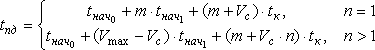 ,
,
где n = ém / (Vmax – Vс)ù есть количество пакетов, на которое разбивается передаваемое сообщение, величина Vmax определяет максимальный размер пакета, который может быть доставлен в сети (по умолчанию для операционной системы MS Windows в сети Fast Ethernet Vmax = 1500 байт), а Vс есть объем служебных данных в каждом из пересылаемых пакетов (для протокола TCP/IP, ОС Windows 2000 и сети Fast Ethernet Vс = 78 байт). Поясним также, что в приведенных соотношениях константа tнач0 характеризует аппаратную составляющую латентности и зависит от параметров используемого сетевого оборудования, значение tнач1 задает время подготовки одного байта данных для передачи по сети. Как результат, величина латентности
tн = tнач0 + ν· tнач1
увеличивается линейно в зависимости от объема передаваемых данных. При этом предполагается, что подготовка данных для передачи второго и всех последующих пакетов может быть совмещена с пересылкой по сети предшествующих пакетов и латентность, тем самым, не может превышать величины
tн = tнач0 + (Vmax – Vс)· tнач1
Помимо латентности, в предлагаемых выражениях для оценки трудоемкости коммуникационной операции уточнено и правило вычисления времени передачи данных
(m + Vс· n) ·tк
что позволяет теперь учитывать эффект увеличения объема передаваемых данных при росте числа пересылаемых пакетов за счет добавления служебной информации (заголовков пакетов).
3. Завершая анализ проблемы построения теоретических оценок трудоемкости коммуникационных операций, следует отметить, что для практического применения перечисленных моделей необходимо выполнить оценку значений параметров используемых соотношений. В этом отношении полезным может оказаться использование и более простых способов вычисления временных затрат на передачу данных - среди известных схем подобного вида подход, в котором трудоемкость операции коммуникации между двумя процессорными узлами кластера оценивается в соответствии с выражением (модель С)
tпд(m) = tн + m / R,
где R есть пропускная способность сети передачи данных.
4. Для проверки адекватности рассмотренных моделей реальным процессам передачи данных приведем результаты выполненных экспериментов в сети многопроцессорного кластера Нижегородского университета (компьютеры IBM PC Pentium 4 1300 Mгц, 256 MB RAM, 10/100 Fast Etherrnet card). При проведении экспериментов для реализации коммуникационных операций использовалась библиотека MPI [1].
Часть экспериментов была выполнена для оценки параметров моделей:
R = 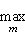 (tпд(m) / m),
(tпд(m) / m),
значения величин tнач0 и tнач1 оценивались при помощи линейной аппроксимации времен передачи сообщений размера от 0 до Vmax.
В ходе экспериментов осуществлялась передача данных между двумя процессорами кластера, размер передаваемых сообщений варьировался от 0 до 8 Мб. Для получения более точных оценок выполнение каждой операции осуществлялось многократно (более 100000 раз), после чего результаты временных замеров усреднялись. Для иллюстрации ниже приведен результат одного эксперимента, при проведении которого размер передаваемых сообщений изменялся от 0 до 1500 байт с шагом 4 байта.
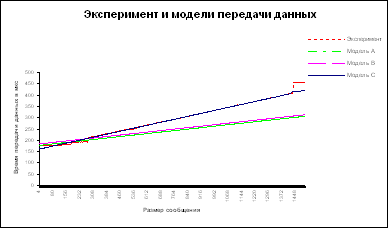
Рис. 3.3. Зависимость экспериментального времени и времени, полученного по моделям A, B, C, от объема данных
В табл. 3.3 приводятся ряд числовых данных по погрешности рассмотренных моделей трудоемкости коммуникационных операций (величина погрешности дается в виде относительного отклонения от реального времени выполнения операции передачи данных).
Таблица 3.3. Погрешность моделей трудоемкости операций передачи данных (по результатам вычислительных экспериментов)
| Объем сообщения в байтах | Время передачи данных в мкс | Погрешность теоретической оценки времени выполнения операции передачи данных | ||
|---|---|---|---|---|
| Модель А | Модель B | Модель C | ||
| 32 | 172,0269 | -16,36% | 3,55% | -12,45% |
| 64 | 172,2211 | -17,83% | 0,53% | -13,93% |
| 128 | 173,1494 | -20,39% | -5,15% | -16,50% |
| 256 | 203,7902 | -7,70% | 0,09% | -4,40% |
| 512 | 242,6845 | 0,46% | -1,63% | 3,23% |
| 1024 | 334,4392 | 14,57% | 0,50% | 16,58% |
| 2048 | 481,5397 | 22,33% | 5,05% | 23,73% |
| 4096 | 770,6155 | 28,55% | 18,13% | 29,42% |
В результате приведенных данных можно заключить, что использование новой предложенной модели (модели В) позволяет оценивать время выполняемых операция передачи данных с более высокой точностью.