Рассмотрим для первоначального ознакомления со способами построения и анализа параллельных методов вычислений сравнительно простую задачу нахождения частных сумм последовательности числовых значений
![]() ,
,
где ![]() есть количество суммируемых значений (данная задача известна также под названием
prefix sum problem – см.
п. 3.3).
есть количество суммируемых значений (данная задача известна также под названием
prefix sum problem – см.
п. 3.3).
Изучение возможных параллельных методов решения данной задачи начнем с еще более простого варианта ее постановки – с задачи вычисления общей суммы имеющегося набора значений (в таком виде задача суммирования является частным случаем общей задачи редукции – см. п. 3.3.)
![]() .
.
Традиционный алгоритм для решения этой задачи состоит в последовательном суммировании элементов числового набора
![]()
Вычислительная схема данного алгоритма может быть представлена следующим образом (см. рис. 4.1):
![]() ,
,
где ![]() есть множество операций
суммирования (вершины
есть множество операций
суммирования (вершины ![]() обозначают операции ввода, каждая
вершина
обозначают операции ввода, каждая
вершина ![]() ,
, ![]() , соответствует прибавлению значения
, соответствует прибавлению значения
![]() к накапливаемой сумме
к накапливаемой сумме ![]() ), а
), а
![]()
есть множество дуг, определяющих информационные зависимости операций.

Рис. 4.1. Последовательная вычислительная схема алгоритма суммирования
Как можно заметить, данный "стандартный" алгоритм суммирования допускает только строго последовательное исполнение и не может быть распараллелен.
Параллелизм алгоритма суммирования становится возможным только при ином способе построения процесса вычислений, основанном на использовании ассоциативности операции сложения. Получаемый новый вариант суммирования (известный в литературе как каскадная схема) состоит в следующем (см. рис. 4.2):
Данная вычислительная
схема может быть определена как граф (пусть ![]() )
)
![]() ,
,

Рис. 4.2. Каскадная схема алгоритма суммирования
где ![]() есть вершины графа (
есть вершины графа (![]() - операции ввода,
- операции ввода, ![]() - операции
первой итерации и т.д.), а множество дуг графа определяется соотношениями:
- операции
первой итерации и т.д.), а множество дуг графа определяется соотношениями:
![]() .
.
Как можно оценить, количество итераций каскадной схемы оказывается равным величине
![]() ,
,
а общее количество операций суммирования
![]()
совпадает с количеством операций последовательного варианта алгоритма суммирования. При параллельном исполнении отдельных итераций каскадной схемы общее количество параллельных операций суммирования является равным
![]() .
.
Как результат, можно оценить показатели ускорения и эффективности каскадной схемы алгоритма суммирования
![]()
![]()
где ![]() есть необходимое для выполнения каскадной схемы количество процессоров.
есть необходимое для выполнения каскадной схемы количество процессоров.
Анализируя полученные характеристики, можно отметить, что время параллельного выполнения каскадной схемы совпадает с оценкой для паракомпьютера в теореме 2 (см. раздел 2). Однако при этом эффективность использования процессоров уменьшается при увеличении количества суммируемых значений
![]() .
.
Получение асимптотически ненулевой эффективности может быть обеспечено, например, при использовании модифицированной каскадной схемы [18]. В новом варианте каскадной схемы все проводимые вычисления подразделяется на два последовательно выполняемых этапа суммирования (см. рис. 4.3):

Рис. 4.3. Модифицированная каскадная схема суммирования
Для упрощения построения
оценок можно предположить ![]() . Тогда для выполнения первого
этапа требуется выполнение
. Тогда для выполнения первого
этапа требуется выполнение ![]() параллельных операций при использовании
параллельных операций при использовании
![]() процессоров. Для выполнения второго
этапа необходимо
процессоров. Для выполнения второго
этапа необходимо
![]()
параллельных операций
для ![]() процессоров. Как результат, данный
способ суммирования характеризуется следующими показателями:
процессоров. Как результат, данный
способ суммирования характеризуется следующими показателями:
![]() ,
, ![]() .
.
С учетом полученных оценок показатели ускорения и эффективности модифицированной каскадной схемы определяются соотношениями:
![]()
![]()
Сравнивая данные оценки с показателями обычной каскадной схемы, можно отметить, что ускорение для предложенного параллельного алгоритма уменьшилось в 2 раза (по сравнению с обычной каскадной схемой), однако для эффективности нового метода суммирования можно получить асимптотически ненулевую оценку снизу
![]()
![]() .
.
Можно отметить также, что данные значения показателей достигаются при количестве процессоров, определенном в теореме 5 (см. раздел 2).
Вернемся к исходной задаче вычисления всех частных сумм последовательности значений и проведем анализ возможных способов последовательной и параллельной организации вычислений. Вычисление всех частных сумм на скалярном компьютере может быть получено при помощи того же самого обычного последовательного алгоритма суммирования при том же количестве операций (!)
![]() .
.
При параллельном исполнении
применение каскадной схемы в явном виде не приводит к желаемым результатам;
достижение эффективного распараллеливания требует привлечения новых подходов
(может даже не имеющих аналогов при последовательном программировании) для разработки
новых параллельно-ориентированных алгоритмов решения задач. Так, для рассматриваемой
задачи нахождения всех частных сумм алгоритм, обеспечивающий получение результатов
за ![]() параллельных операций (как и в
случае вычисления общей суммы), может состоять в следующем (см. рис. 4.4) [18]:
параллельных операций (как и в
случае вычисления общей суммы), может состоять в следующем (см. рис. 4.4) [18]:
![]() .
.

Рис.
4.4. Схема параллельного алгоритма вычисления всех частных сумм (величины ![]() означают суммы значений от
означают суммы значений от ![]() до
до ![]() элементов числовой
последовательности)
элементов числовой
последовательности)
Всего параллельный алгоритм
выполняется за ![]() параллельных операций сложения.
На каждой итерации алгоритма параллельно выполняются
параллельных операций сложения.
На каждой итерации алгоритма параллельно выполняются ![]() скалярных операций сложения
и, таким образом, общее количество выполняемых скалярных операций определяется
величиной
скалярных операций сложения
и, таким образом, общее количество выполняемых скалярных операций определяется
величиной
![]()
(параллельный алгоритм
содержит большее (!) количество операций по сравнению с последовательным способом
суммирования). Необходимое количество процессоров определяется количеством суммируемых
значений (![]() ).
).
С учетом полученных соотношений, показатели ускорения и эффективности параллельного алгоритма вычисления всех частных сумм оцениваются следующим образом:
![]()
![]() .
.
Как следует из построенных оценок, эффективность алгоритма также уменьшается при увеличении числа суммируемых значений и при необходимости повышения величины этого показателя может оказаться полезной модификация алгоритма как и в случае с обычной каскадной схемой.
Задача умножения матрицы на вектор определяется соотношениями
![]() .
.
Тем самым, получение результирующего вектора ![]() предполагает повторения
предполагает повторения ![]() однотипных
операций по умножению строк матрицы
однотипных
операций по умножению строк матрицы ![]() и вектора
и вектора ![]() . Получение каждой такой
операции включает поэлементное умножение элементов строки матрицы и вектора
. Получение каждой такой
операции включает поэлементное умножение элементов строки матрицы и вектора
![]() и последующее суммирование полученных произведений. Общее количество необходимых
скалярных операций оценивается величиной
и последующее суммирование полученных произведений. Общее количество необходимых
скалярных операций оценивается величиной
![]() .
.
Как следует из выполняемых действий при умножении матрицы и вектора, параллельные способы решения задачи могут быть получены на основе параллельных алгоритмов суммирования (см. параграф 4.1). В данном разделе анализ способов распараллеливания будет дополнен рассмотрением вопросов организации параллельных вычислений в зависимости от количества доступных для использования процессоров. Кроме того, на примере задачи умножения матрицы на вектор будут обращено внимание на необходимость выбора наиболее подходящей топологии вычислительной системы (существующих коммуникационных каналов между процессорами) для снижения затрат для организации межпроцессорного взаимодействия.
1. Выбор параллельного способа вычислений. Выполним анализ информационных зависимостей в алгоритме умножения матрицы на вектор для выбора возможных способов распараллеливания. Как можно заметить
- выполняемые при проведении вычислений операции умножения отдельных строк матрицы на вектор являются независимыми и могут быть выполнены параллельно;
- умножение каждой строки на вектор включает независимые операции поэлементного умножения и тоже могут быть выполнены параллельно;
- суммирование получаемых произведений в каждой операции умножения строки матрицы на вектор могут быть выполнены по одному из ранее рассмотренных вариантов алгоритма суммирования (последовательный алгоритм, обычная и модифицированная каскадные схемы).
Таким образом, максимально необходимое количество процессоров определяется величиной
![]() .
.
Использование такого количества процессоров может быть
представлено следующим образом. Множество процессоров ![]() разбивается на
разбивается на ![]() групп
групп
![]() ,
,
каждая из которых представляет
набор процессоров для выполнения операции умножения отдельной строки матрицы
на вектор. В начале вычислений на каждый процессор группы пересылаются элемент
строки матрицы ![]() и соответствующий элемент вектора
и соответствующий элемент вектора
![]() .
Далее каждый процессор выполняет операцию умножения. Последующие затем вычисления
выполняются по каскадной схеме суммирования. Для иллюстрации на рис. 4.5 приведена
вычислительная схема для процессоров группы
.
Далее каждый процессор выполняет операцию умножения. Последующие затем вычисления
выполняются по каскадной схеме суммирования. Для иллюстрации на рис. 4.5 приведена
вычислительная схема для процессоров группы ![]() при размерности матрицы
при размерности матрицы
![]() .
.

Рис. 4.5. Вычислительная схема операции умножения строки матрицы на вектор
2. Оценка показателей
эффективности алгоритма. Время выполнения
параллельного алгоритма при использовании ![]() процессоров определяется
временем выполнения параллельной операции умножения и временем выполнения каскадной
схемы
процессоров определяется
временем выполнения параллельной операции умножения и временем выполнения каскадной
схемы
![]() .
.
Как результат, показатели эффективности алгоритма определяются следующими соотношениями:
![]() ,
, ![]() ,
,
![]() .
.
3. Выбор топологии вычислительной системы. Для рассматриваемой задачи умножения матрицы на вектор
наиболее подходящими топологиями являются структуры, в которых обеспечивается
быстрая передача данных (пути единичной длины) в каскадной схеме суммирования
(см. рис. 4.5). Таковыми топологиями являются структура с полной системой связей
(полный граф) и гиперкуб. Другие топологии приводят к возрастанию
коммуникационного времени из-за удлинения маршрутов передачи данных. Так, при
линейном упорядочивании процессоров с системой связей только с ближайшими соседями
слева и справа (линейка или кольцо) для каскадной схемы длина
пути передачи каждой получаемой частичной суммы на итерации ![]() ,
,
![]() ,
является равной
,
является равной ![]() . Если принять, что передача данных
по маршруту длины
. Если принять, что передача данных
по маршруту длины ![]() в топологиях с линейной структурой
требует выполнения
в топологиях с линейной структурой
требует выполнения ![]() операций передачи данных, общее
количество параллельных операций (суммарной длительности путей) передачи данных
определяется величиной
операций передачи данных, общее
количество параллельных операций (суммарной длительности путей) передачи данных
определяется величиной
![]()
(без учета передач данных для начальной загрузки процессоров).
Применение вычислительной
системы с топологией в виде прямоугольной двумерной решетки размера ![]() приводит к простой и наглядной интерпретации выполняемых вычислений (структура
сети соответствует структуре обрабатываемых данных). Для такой топологии строки
матрицы
приводит к простой и наглядной интерпретации выполняемых вычислений (структура
сети соответствует структуре обрабатываемых данных). Для такой топологии строки
матрицы ![]() наиболее целесообразно разместить по горизонталям решетки; в этом случае элементы
вектора
наиболее целесообразно разместить по горизонталям решетки; в этом случае элементы
вектора ![]() должны быть разосланы по вертикалям вычислительной системы. Выполнение вычислений
при таком размещении данных может осуществляться параллельно по строкам решетки;
как результат, общее количество передач данных совпадает с результатами для
линейки (
должны быть разосланы по вертикалям вычислительной системы. Выполнение вычислений
при таком размещении данных может осуществляться параллельно по строкам решетки;
как результат, общее количество передач данных совпадает с результатами для
линейки (![]() ).
).
Коммуникационные действия, выполняемые при решении поставленной задачи, состоят в передаче данных между парами процессоров МВС. Подробный анализ длительности реализации таких операций проведен в п. 3.3.
4. Рекомендации по реализации параллельного алгоритма. При реализации параллельного алгоритма целесообразно
выделить начальный этап по загрузке используемых процессоров исходными данными.
Наиболее просто такая инициализация обеспечивается при топологии вычислительной
системы с топологией в виде полного графа (загрузка обеспечивается при
помощи одной параллельной операции пересылки данных). При организации множества
процессоров в виде гиперкуба может оказаться полезной двухуровневое управление
процессом начальной загрузки, при которой центральный управляющий процессор
обеспечивает рассылку строк матрицы и вектора к управляющим процессорам процессорных
групп ![]() ,
, ![]() , которые, в свою очередь, рассылают
элементы строк матрицы и вектора по исполнительным процессорам. Для топологий
в виде линейки или кольца требуется
, которые, в свою очередь, рассылают
элементы строк матрицы и вектора по исполнительным процессорам. Для топологий
в виде линейки или кольца требуется ![]() последовательных операций
передачи данных с последовательно убывающим объемом пересылаемых данных от
последовательных операций
передачи данных с последовательно убывающим объемом пересылаемых данных от ![]() до
до ![]() элементов.
элементов.
1. Выбор параллельного
способа вычислений. При уменьшении
доступного количества используемых процессоров (![]() ) обычная
каскадная схема суммирования при выполнении операций умножения строк матрицы
на вектор становится не применимой. Для простоты изложения материала положим
) обычная
каскадная схема суммирования при выполнении операций умножения строк матрицы
на вектор становится не применимой. Для простоты изложения материала положим
![]() и воспользуется
модифицированной каскадной схемой. Начальная нагрузка каждого процессора в этом
случае увеличивается и процессор загружается (
и воспользуется
модифицированной каскадной схемой. Начальная нагрузка каждого процессора в этом
случае увеличивается и процессор загружается (![]() ) частями строк
матрицы
) частями строк
матрицы ![]() и вектора
и вектора ![]() . Время выполнения операции
умножения матрицы на вектор может быть оценено как величина
. Время выполнения операции
умножения матрицы на вектор может быть оценено как величина
![]()
![]() .
.
При использовании количества
процессоров, необходимого для реализации модифицированной каскадной схемы, т.е.
при ![]() , данное выражение дает оценку
времени исполнения
, данное выражение дает оценку
времени исполнения ![]() (при
(при ![]() ).
).
При количестве процессоров
![]() , когда время выполнения алгоритма
оценивается как
, когда время выполнения алгоритма
оценивается как ![]() , может быть предложена новая схема
параллельного выполнения вычислений, при которой для каждой итерации каскадного
суммирования используются неперекрывающиеся наборы процессоров. При таком
походе имеющегося количества процессоров оказывается достаточным для реализации
только одной операции умножения строки матрицы
, может быть предложена новая схема
параллельного выполнения вычислений, при которой для каждой итерации каскадного
суммирования используются неперекрывающиеся наборы процессоров. При таком
походе имеющегося количества процессоров оказывается достаточным для реализации
только одной операции умножения строки матрицы ![]() и вектора
и вектора ![]() . Кроме того,
при выполнении очередной итерации каскадного суммирования процессоры, ответственные
за исполнение всех предшествующих итераций, являются свободными. Однако этот
недостаток предлагаемого подхода можно обратить в достоинство, задействовав
простаивающие процессоры для обработки следующих строк матрицы
. Кроме того,
при выполнении очередной итерации каскадного суммирования процессоры, ответственные
за исполнение всех предшествующих итераций, являются свободными. Однако этот
недостаток предлагаемого подхода можно обратить в достоинство, задействовав
простаивающие процессоры для обработки следующих строк матрицы ![]() . В результате
может быть сформирована следующая схема конвейерного выполнения умножения
матрицы и вектора:
. В результате
может быть сформирована следующая схема конвейерного выполнения умножения
матрицы и вектора:
-
множество процессоров ![]() разбивается
на непересекающиеся процессорные группы
разбивается
на непересекающиеся процессорные группы
![]()
![]() ,
,
при этом группа ![]() ,
, ![]() , состоит из
, состоит из ![]() процессоров и используется
для выполнения
процессоров и используется
для выполнения ![]() итерации каскадного алгоритма
(группа
итерации каскадного алгоритма
(группа ![]() применяется для реализации поэлементного умножения); общее количество процессоров
применяется для реализации поэлементного умножения); общее количество процессоров
![]() ;
;
-
инициализация вычислений состоит
в поэлементной загрузке процессоров группы ![]() значениями 1 строки матрицы и
вектора
значениями 1 строки матрицы и
вектора ![]() ;
после начальной загрузки выполняется параллельная операция поэлементного умножения
и последующей реализации обычной каскадной схемы суммирования;
;
после начальной загрузки выполняется параллельная операция поэлементного умножения
и последующей реализации обычной каскадной схемы суммирования;
-
при выполнении вычислений каждый
раз после завершения операции поэлементного умножения осуществляется загрузка
процессоров группы ![]() элементами очередной строки матрицы
и инициируется процесс вычислений для вновь загруженных данных.
элементами очередной строки матрицы
и инициируется процесс вычислений для вновь загруженных данных.
В результате применения описанного алгоритма множество
процессоров ![]() реализует конвейер для выполнения
операции умножения строки матрицы на вектор. На подобном конвейере одновременно
могут находиться несколько отдельных строк матрицы на разных стадиях обработки.
Так, например, после поэлементного умножения элементов первой строки и вектора
реализует конвейер для выполнения
операции умножения строки матрицы на вектор. На подобном конвейере одновременно
могут находиться несколько отдельных строк матрицы на разных стадиях обработки.
Так, например, после поэлементного умножения элементов первой строки и вектора
![]() процессоры группы
процессоры группы ![]() будут выполнять
первую итерацию каскадного алгоритма для первой строки матрицы, а процессоры
группы
будут выполнять
первую итерацию каскадного алгоритма для первой строки матрицы, а процессоры
группы ![]() будут исполнять поэлементное умножение
значений второй строки матрицы и т.д. Для иллюстрации на рис. 4.6 приведена
ситуация процесса вычислений после 2 итераций конвейера при
будут исполнять поэлементное умножение
значений второй строки матрицы и т.д. Для иллюстрации на рис. 4.6 приведена
ситуация процесса вычислений после 2 итераций конвейера при ![]() .
.
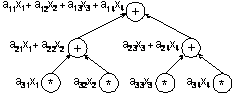
Рис. 4.6. Состояние конвейера для операции умножения строки матрицы на вектор после выполнения 2 итераций
2. Оценка показателей
эффективности алгоритма. Умножение
первой строки на вектор в соответствии с каскадной схемой будет завершено, как
и обычно, после выполнения (![]() ) параллельных операций. Для других
же строк – в соответствии с конвейерной схемой организации вычислений - появление
результатов умножения каждой очередной строки будет происходить после завершения
каждой последующей итерации конвейера. Как результат, общее время выполнения
операции умножения матрицы на вектор может быть выражено величиной
) параллельных операций. Для других
же строк – в соответствии с конвейерной схемой организации вычислений - появление
результатов умножения каждой очередной строки будет происходить после завершения
каждой последующей итерации конвейера. Как результат, общее время выполнения
операции умножения матрицы на вектор может быть выражено величиной
![]() .
.
Данная оценка является
несколько большей, чем время выполнения параллельного алгоритма, описанного
в предыдущем пункте (![]() ), однако вновь предлагаемый способ
требует меньшего количества передаваемых данных (вектор
), однако вновь предлагаемый способ
требует меньшего количества передаваемых данных (вектор ![]() пересылается
только однократно). Кроме того, использование конвейерной схемы приводит к более
раннему появлению части результатов вычислений (что может быть полезным в ряде
ситуаций обработки данных).
пересылается
только однократно). Кроме того, использование конвейерной схемы приводит к более
раннему появлению части результатов вычислений (что может быть полезным в ряде
ситуаций обработки данных).
Как результат, показатели эффективности алгоритма определяются соотношениями следующего вида:
![]() ,
, ![]() ,
,
![]() .
.
3. Выбор топологии вычислительной системы. Целесообразная топология вычислительной системы полностью
определяется вычислительной схемой – это полное бинарное дерево высотой
![]() .
Количество передач данных при такой топологии сети определяется общим количеством
итераций, выполняемых конвейером, т.е.
.
Количество передач данных при такой топологии сети определяется общим количеством
итераций, выполняемых конвейером, т.е.
![]() .
.
Инициализация вычислений начинается с листьев дерева, результаты суммирования накапливаются в корневом процессоре.
Анализ трудоемкости выполняемых коммуникационных действий для вычислительных систем с другими топологиями межпроцессорных связей предполагается осуществить в качестве самостоятельного задания (см. также п. 3.4).
1. Выбор параллельного
способа вычислений. При использовании
![]() процессоров для умножения матрицы
процессоров для умножения матрицы
![]() на вектор
на вектор ![]() может быть использован ранее уже рассмотренный в пособии параллельный алгоритм
построчного умножения, при котором строки матрицы распределяются по процессорам
построчно и каждый процессор реализует операцию умножения какой-либо отдельной
строки матрицы
может быть использован ранее уже рассмотренный в пособии параллельный алгоритм
построчного умножения, при котором строки матрицы распределяются по процессорам
построчно и каждый процессор реализует операцию умножения какой-либо отдельной
строки матрицы ![]() на вектор
на вектор![]() . Другой возможный способ
организации параллельных вычислений может состоять в построении конвейерной
схемы для операции умножения строки матрицы на вектор (скалярного произведения
векторов) путем расположения всех имеющихся процессоров в виде линейной
последовательности (линейки).
. Другой возможный способ
организации параллельных вычислений может состоять в построении конвейерной
схемы для операции умножения строки матрицы на вектор (скалярного произведения
векторов) путем расположения всех имеющихся процессоров в виде линейной
последовательности (линейки).
Подобная схема вычислений может быть определена следующим образом. Представим множество процессоров в виде линейной последовательности (см. рис. 4.7):
![]() ;
;
каждый процессор ![]() ,
,
![]() ,
используется для умножения элементов
,
используется для умножения элементов ![]() столбца матрицы и
столбца матрицы и ![]() элемента вектора
элемента вектора
![]() .
Выполнение вычислений на каждом процессоре
.
Выполнение вычислений на каждом процессоре ![]() ,
, ![]() , состоит в следующем:
, состоит в следующем:
-
запрашивается очередной элемент
![]() столбца матрицы;
столбца матрицы;
-
выполняется умножение элементов
![]() и
и ![]() ;
;
-
запрашивается результат вычислений
![]() предшествующего процессора;
предшествующего процессора;
-
выполняется сложение значений ![]() ;
;
-
полученный результат ![]() пересылается
следующему процессору.
пересылается
следующему процессору.
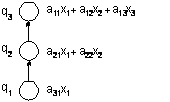
Рис. 4.7. Состояние линейного конвейера для операции умножения строки матрицы на вектор после выполнения двух итераций
При инициализации описанной схемы необходимо выполнить ряд дополнительных действий:
-
при выполнении первой итерации
каждый процессор дополнительно запрашивает элемент вектора ![]() ;
;
-
для синхронизации вычислений (при
выполнении очередной итерации схемы запрашивается результат вычисления предшествующего
процессора) на этапе инициализации процессор ![]() ,
, ![]() , выполняет
(
, выполняет
(![]() ) цикл ожидания.
) цикл ожидания.
Кроме того, для однородности
описанной схемы для первого процессора ![]() , у которого нет предшествующего
процессора, целесообразно ввести пустую операцию сложения (
, у которого нет предшествующего
процессора, целесообразно ввести пустую операцию сложения (![]() ).
).
Для иллюстрации на рис.
4.7 показано состояние процесса вычислений после второй итерации конвейера при
![]() .
.
2. Оценка показателей эффективности алгоритма. Умножение первой строки на вектор в соответствии с
описанной конвейерной схемой будет завершено после выполнения (![]() ) параллельных
операций. Результат умножения следующих строк будет происходить после завершения
каждой очередной итерации конвейера (напомним, итерация каждого процессора включает
выполнение операций умножения и сложения). Как результат, общее время выполнения
операции умножения матрицы на вектор может быть выражено соотношением:
) параллельных
операций. Результат умножения следующих строк будет происходить после завершения
каждой очередной итерации конвейера (напомним, итерация каждого процессора включает
выполнение операций умножения и сложения). Как результат, общее время выполнения
операции умножения матрицы на вектор может быть выражено соотношением:
![]() .
.
Данная оценка также
является большей, чем минимально возможное время ![]() выполнения
параллельного алгоритма при
выполнения
параллельного алгоритма при ![]() . Полезность использования конвейерной
вычислительной схемы состоит, как отмечалось в предыдущем пункте, в уменьшении
количества передаваемых данных и в более раннем появлении части результатов
вычислений.
. Полезность использования конвейерной
вычислительной схемы состоит, как отмечалось в предыдущем пункте, в уменьшении
количества передаваемых данных и в более раннем появлении части результатов
вычислений.
Показатели эффективности данной вычислительной схемы определяются соотношениями:
![]() ,
, ![]() ,
,
![]() .
.
3. Выбор топологии вычислительной системы. Необходимая топология вычислительной системы для выполнения описанного алгоритма однозначно определяется предлагаемой вычислительной схемой – это линейно упорядоченное множество процессоров (линейка).
1. Выбор параллельного способа вычислений. При уменьшении количества процессоров до величины ![]() параллельная
вычислительная схема умножения матрицы на вектор может быть получена в результате
адаптации алгоритма построчного умножения. В этом случае каскадная схема суммирования
результатов поэлементного умножения вырождается и операция умножения строки
матрицы на вектор полностью выполняется на единственном процессоре. Получаемая
при таком подходе вычислительная схема может быть конкретизирована следующим
образом:
параллельная
вычислительная схема умножения матрицы на вектор может быть получена в результате
адаптации алгоритма построчного умножения. В этом случае каскадная схема суммирования
результатов поэлементного умножения вырождается и операция умножения строки
матрицы на вектор полностью выполняется на единственном процессоре. Получаемая
при таком подходе вычислительная схема может быть конкретизирована следующим
образом:
-
на каждый из имеющихся процессоров
пересылается вектор ![]() и
и ![]() строк матрицы;
строк матрицы;
- выполнение операции умножения строк матрица на вектор выполняется при помощи обычного последовательного алгоритма.
Следует отметить, что размер матрицы может оказаться не кратным количеству процессоров и тогда строки матрицы не могут быть разделены поровну между процессорами. В этих ситуациях можно отступить от требования равномерности загрузки процессоров и для получения более простой вычислительной схемы принять правило, что размещение данных на процессорах осуществляется только построчно (т.е. элементы одной строки матрицы не могут быть разделены между несколькими процессорами). Неодинаковое количество строк приводит к разной вычислительной нагрузке процессоров; тем самым, завершение вычислений (общая длительность решения задачи) будет определяться временем работы наиболее загруженного процессора (при этом часть от этого общего времени отдельные процессоры могут простаивать из-за исчерпания своей доли вычислений). Неравномерность загрузки процессоров снижает эффективность использования МВС и, как результат рассмотрения данного примера можно заключить, что проблема балансировки относится к числу важнейших задач параллельного программирования.
2. Оценка показателей эффективности алгоритма. Время выполнения параллельного алгоритма определяется оценкой
![]() ,
,
где величина ![]() есть наибольшее количество строк,
загружаемых на один процессор. С учетом данной оценки показатели эффективности
предлагаемой вычислительной схемы имеют вид:
есть наибольшее количество строк,
загружаемых на один процессор. С учетом данной оценки показатели эффективности
предлагаемой вычислительной схемы имеют вид:
![]() ,
, ![]() .
.
При кратности размера матрицы и количества процессоров показатели ускорения и эффективности алгоритма приводятся к виду:
![]() ,
, ![]()
и принимают, тем самым, максимально возможные значения.
3. Выбор топологии вычислительной системы. В соответствии с характером выполняемых межпроцессорных взаимодействий в предложенной вычислительной схеме в качестве возможной топологии МВС может служить организация процессоров в виде звезды (см. рис. 1.1). Управляющий процессор подобной топологии может использоваться для загрузки вычислительных процессоров исходными данными и для приема результатов выполненных вычислений.
Задача умножения матрицы на матрицу определяется соотношениями
![]() .
.
(для простоты изложения материала будем предполагать,
что перемножаемые матрицы ![]() и
и ![]() являются квадратными и имеют порядок
являются квадратными и имеют порядок
![]() ).
).
Анализ возможных способов параллельного выполнения данной задачи может быть проведен по аналогии с рассмотрением задачи умножения матрицы на вектор. Оставив подобный анализ для самостоятельного изучения, покажем на примере задачи матричного умножения использование нескольких общих подходов, позволяющих формировать параллельные способы решения сложных задач.
Задача матричного умножения требует для своего
решения выполнение большого количества операций (![]() скалярных умножений
и сложений). Информационный граф алгоритма при большом размере матриц становится
достаточно объемным и, как результат, непосредственный анализ этого графа затруднен.
После выявления информационной независимости выполняемых вычислений могут быть
предложены многочисленные способы распараллеливания алгоритма.
скалярных умножений
и сложений). Информационный граф алгоритма при большом размере матриц становится
достаточно объемным и, как результат, непосредственный анализ этого графа затруднен.
После выявления информационной независимости выполняемых вычислений могут быть
предложены многочисленные способы распараллеливания алгоритма.
С другой стороны, алгоритм выполнения матричного
умножения может быть рассмотрен как процесс решения ![]() независимых подзадач умножения
матрицы
независимых подзадач умножения
матрицы ![]() на столбцы матрицы
на столбцы матрицы ![]() . Введение макроопераций, как можно
заметить по рис. 4.8, приводит к более компактному представлению информационного
графа алгоритма, значительно упрощает проблему выбора эффективных способов распараллеливания
вычислений, позволяет использовать типовые параллельные методы выполнения макроопераций
в качестве конструктивных элементов при разработке параллельных способов решения
сложных вычислительных задач.
. Введение макроопераций, как можно
заметить по рис. 4.8, приводит к более компактному представлению информационного
графа алгоритма, значительно упрощает проблему выбора эффективных способов распараллеливания
вычислений, позволяет использовать типовые параллельные методы выполнения макроопераций
в качестве конструктивных элементов при разработке параллельных способов решения
сложных вычислительных задач.
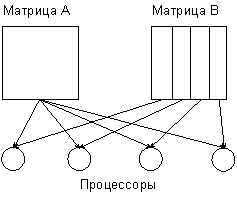
Рис. 4.8. Вычислительная схема матричного умножения при использовании макроопераций умножения матрицы A на столбец матрицы B
Важно отметить, что процесс введения макроопераций может осуществляться поэтапно с последовательно возрастающим уровнем детализации используемых операций. Так, для задачи матричного умножения после построения графа вычислений на основе макроопераций умножения матрицы на вектор может быть выполнено рассмотрение каждой макрооперации как последовательности независимых операций скалярного произведения векторов и т.п. Подобная иерархическая декомпозиционная методика построения параллельных методов решения сложных задач является одной из основных в параллельном программировании и широко используется в практике.
При построении параллельных способов выполнения матричного умножения наряду с рассмотрением матриц в виде наборов строк и столбцов широко используется блочное представление матриц. Выполним более подробное рассмотрение данного способа организации вычислений.
Пусть количество процессоров составляет ![]() , а количество
строк и столбцов матрицы является кратным величине
, а количество
строк и столбцов матрицы является кратным величине ![]() , т.е.
, т.е. ![]() . Представим
исходные матрицы
. Представим
исходные матрицы ![]() ,
, ![]() и результирующую матрицу
и результирующую матрицу ![]() в виде наборов
прямоугольных блоков размера
в виде наборов
прямоугольных блоков размера ![]() . Тогда операцию матричного умножения
матриц
. Тогда операцию матричного умножения
матриц ![]() и
и ![]() в блочном виде можно представить
следующим образом:
в блочном виде можно представить
следующим образом:
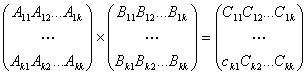 ,
,
где каждый блок ![]() матрицы
матрицы ![]() определяется в соответствии
с выражением
определяется в соответствии
с выражением
![]() .
.
Информационный граф алгоритма умножения при подобном
представлении матриц показан на рис. 4.9 (на рисунке представлен фрагмент графа
для вычисления только одного блока матрицы ![]() ). При анализе этого графа можно
обратить внимание на взаимную независимость вычислений блоков
). При анализе этого графа можно
обратить внимание на взаимную независимость вычислений блоков ![]() матрицы
матрицы ![]() . Как результат,
возможный подход для параллельного выполнения вычислений может состоять в выделении
для расчетов, связанных с получением отдельных блоков
. Как результат,
возможный подход для параллельного выполнения вычислений может состоять в выделении
для расчетов, связанных с получением отдельных блоков ![]() , разных процессоров.
Применение подобного подхода позволяет получить многие эффективные параллельные
методы умножения блочно-представленных матриц; один из алгоритмов данного
класса рассматривается ниже.
, разных процессоров.
Применение подобного подхода позволяет получить многие эффективные параллельные
методы умножения блочно-представленных матриц; один из алгоритмов данного
класса рассматривается ниже.

Рис. 4.9. Информационный граф матричного умножения при блочном представлении матриц
Для организации параллельных вычислений предположим,
что процессоры образуют логическую прямоугольную решетку размером ![]() (обозначим
через
(обозначим
через ![]() процессор, располагаемый на пересечении
процессор, располагаемый на пересечении ![]() строки и
строки и ![]() столбца решетки). Основные
положения параллельного метода, известного как алгоритм Фокса (Fox)
[15], состоят в следующем:
столбца решетки). Основные
положения параллельного метода, известного как алгоритм Фокса (Fox)
[15], состоят в следующем:
в ходе вычислений на каждом из
процессоров ![]() располагается четыре матричных
блока:
располагается четыре матричных
блока:
Выполнение параллельного метода включает:
этап вычислений, на каждой итерации ![]() , которого выполняется:
, которого выполняется:
![]() ,
,
(![]() есть операция получения остатка от целого деления);
есть операция получения остатка от целого деления);
полученные в результаты пересылок
блоки ![]() ,
,
![]() каждого процессора
каждого процессора ![]() перемножаются и прибавляются к блоку
перемножаются и прибавляются к блоку ![]()
![]() ;
;
Для пояснения приведенных правил параллельного метода
на рис. 4.10 приведено состояние блоков на каждом процессоре в ходе выполнения
итераций этапа вычислений (для процессорной решетки ![]() ).
).
Приведенный параллельный метод матричного умножения приводит к равномерному распределению вычислительной нагрузки между процессорами
![]() ,
, ![]() .
.
Вместе с тем, блочное
представление матриц приводит к некоторому повышению объема пересылаемых между
процессорами данных - на этапе инициализации и на каждой итерации этапа вычислений
на каждый процессор передается 2 блока данных общим объемом ![]() .
Учитывая выполняемое количество итераций метода, объем пересылаемых данных для
каждого процессора составляет величину
.
Учитывая выполняемое количество итераций метода, объем пересылаемых данных для
каждого процессора составляет величину
![]()
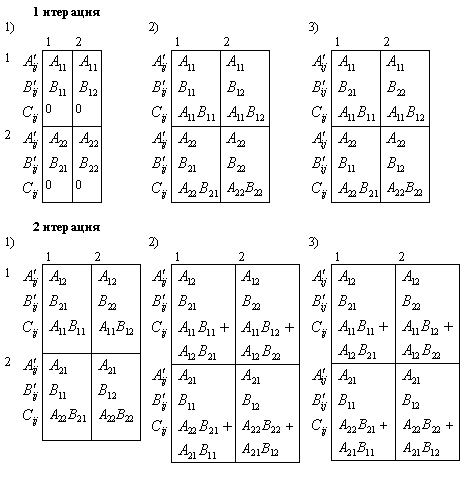
Рис. 4.10. Состояние блоков на каждом процессоре в ходе выполнения итераций этапа вычислений
Объем пересылаемых данных
может быть снижен, например, при использовании строкового (для ![]() )
и столбцового (для
)
и столбцового (для ![]() ) разбиения матриц, при котором
справедлива оценка
) разбиения матриц, при котором
справедлива оценка
![]() .
.
Данные оценки показывают, что различие объемов пересылаемых данных
![]()
является не столь существенным и данное различие уменьшается при увеличении числа используемых процессоров.
С другой стороны, использование блочного представления матриц приводит к ряду положительных моментов. Так, при данном способе организации вычислений пересылка данных оказывается распределенной по времени и это может позволить совместить процессы передачи и обработки данных; блочная структура может быть использована для создания высокоэффективных методов слабо заполненных (разреженных) матриц. И главное – данный метод является примером широко распространенного способа организации параллельных вычислений, состоящего в распределении между процессорами обрабатываемых данных с учетом близости их расположения в содержательных постановках решаемых задач. Подобная идея, часто называемая в литературе геометрическим принципом распараллеливания, широко используется при разработке параллельных методов решения сложных задач, поскольку во многих случаях может приводить к значительному снижению потоков пересылаемых данных за счет локализации на процессорах существенно информационно-зависимых частей алгоритмов (в частности, подобный эффект может быть достигнут при численном решении дифференциальных уравнений в частных производных).
Сортировка является одной из типовых проблем обработки данных, и обычно понимается как задача размещения элементов неупорядоченного набора значений
![]()
в порядке монотонного возрастания или убывания
![]()
(здесь и далее все пояснения для краткости будут даваться только на примере упорядочивания данных по возрастанию).
Возможные способы решения этой задачи широко обсуждаются в литературе; один из наиболее полных обзоров алгоритмов сортировки содержится в работе [7]. Вычислительная трудоемкость процедуры упорядочивания является достаточно высокой. Так, для ряда известных простых методов (пузырьковая сортировка, сортировка включением и др.) количество необходимых операций определяется квадратичной зависимостью от числа упорядочиваемых данных
![]() .
.
Для более эффективных алгоритмов (сортировка слиянием, сортировка Шелла, быстрая сортировка) трудоемкость определяется величиной
![]() .
.
Данное выражение дает
также нижнюю оценку необходимого количества операций для упорядочивания набора
из ![]() значений; алгоритмы с меньшей трудоемкостью могут быть получены только для частных
вариантов задачи.
значений; алгоритмы с меньшей трудоемкостью могут быть получены только для частных
вариантов задачи.
Ускорение сортировки может быть обеспечено при использовании нескольких
(![]() ,
,
![]() ) процессоров.
Исходный упорядочиваемый набор в этом случае разделяется между процессорами;
в ходе сортировки данные пересылаются между процессорами и сравниваются между
собой. Результирующий (упорядоченный) набор, как правило, также разделен между
процессорами; при этом для систематизации такого разделения для процессоров
вводится та или иная система последовательной нумерации и обычно требуется,
чтобы при завершении сортировки значения, располагаемые на процессорах с меньшими
номерами, не превышали значений процессоров с большими номерами.
) процессоров.
Исходный упорядочиваемый набор в этом случае разделяется между процессорами;
в ходе сортировки данные пересылаются между процессорами и сравниваются между
собой. Результирующий (упорядоченный) набор, как правило, также разделен между
процессорами; при этом для систематизации такого разделения для процессоров
вводится та или иная система последовательной нумерации и обычно требуется,
чтобы при завершении сортировки значения, располагаемые на процессорах с меньшими
номерами, не превышали значений процессоров с большими номерами.
Оставляя подробный анализ проблемы сортировки для специального рассмотрения, в пособии основное внимание уделяется изучению параллельных способов выполнения для ряда широко известных методов внутренней сортировки, когда все упорядочиваемые данные могут быть размещены полностью в оперативной памяти ЭВМ.
1. При детальном рассмотрении способов упорядочивания данных, применяемых в алгоритмах сортировки, можно обратить внимание, что многие методы основаны на применении одной и той же базовой операции "сравнить и переставить" (compare-exchange), состоящей в сравнении той или иной пары значений из сортируемого набора данных и перестановки этих значений, если их порядок не соответствует условиям сортировки
// операция "сравнить и переставить"
if ( a[i] > a[j] ) {
temp = a[i];
a[i] = a[j];
a[j] = temp;
}
Целенаправленное применение данной операции позволяет упорядочить данные; в способах выбора пар значений для сравнения собственно и проявляется различие алгоритмов сортировки. Так, например, в пузырьковой сортировке [7] осуществляется последовательное сравнение всех соседних элементов; в результате прохода по упорядочиваемому набору данных в последнем (верхнем) элементе оказывается максимальное значение ("всплывание пузырька"); далее для продолжения сортировки этот уже упорядоченный элемент отбрасывается и действия алгоритма повторяются
// пузырьковая сортировка for ( i=1; i<n; i++ ) for ( j=0; j<n-i; j++ ) <сравнить и переставить элементы (a[j], a[j+1])> }
2. Для параллельного обобщения выделенной базовой операции
сортировки рассмотрим первоначально ситуацию, когда количество процессоров совпадает
с числом сортируемых значений (т.е. ![]() ). Тогда сравнение значений
). Тогда сравнение значений
![]() и
и ![]() ,
располагаемых, например, на процессорах
,
располагаемых, например, на процессорах ![]() и
и ![]() , можно организовать следующим
образом:
, можно организовать следующим
образом:
-
выполнить взаимообмен имеющихся
на процессорах ![]() и
и ![]() значений (с сохранением на этих
процессорах исходных элементов);
значений (с сохранением на этих
процессорах исходных элементов);
-
сравнить на каждом процессоре ![]() и
и ![]() получившиеся
одинаковые пары значений (
получившиеся
одинаковые пары значений (![]() ,
,![]() ); результаты сравнения используются
для разделения данных между процессорами – на одном процессоре (например,
); результаты сравнения используются
для разделения данных между процессорами – на одном процессоре (например, ![]() )
остается меньший элемент, другой процессор (т.е.
)
остается меньший элемент, другой процессор (т.е. ![]() ) запоминает для дальней обработки
большее значение пары
) запоминает для дальней обработки
большее значение пары
![]() ,
, ![]() .
.
3. Рассмотренное параллельное обобщение базовой операции
сортировки может быть надлежащим образом адаптировано и для случая ![]() , когда количество
процессоров является меньшим числа упорядочиваемых значений. В данной ситуации
каждый процессор будет содержать уже не единственное значение, а часть (блок
размера
, когда количество
процессоров является меньшим числа упорядочиваемых значений. В данной ситуации
каждый процессор будет содержать уже не единственное значение, а часть (блок
размера ![]() ) сортируемого набора данных. Эти
блоки обычно упорядочиваются в самом начале сортировки на каждом процессоре
в отдельности при помощи какого-либо быстрого алгоритма (предварительная стадия
параллельной сортировки). Далее, следуя схеме одноэлементного сравнения, взаимодействие
пары процессоров
) сортируемого набора данных. Эти
блоки обычно упорядочиваются в самом начале сортировки на каждом процессоре
в отдельности при помощи какого-либо быстрого алгоритма (предварительная стадия
параллельной сортировки). Далее, следуя схеме одноэлементного сравнения, взаимодействие
пары процессоров ![]() и
и ![]() для совместного упорядочения содержимого
блоков
для совместного упорядочения содержимого
блоков ![]() и
и ![]() может быть осуществлено следующим
образом:
может быть осуществлено следующим
образом:
-
выполнить взаимообмен блоков между
процессорами ![]() и
и ![]() ;
;
-
объединить блоки ![]() и
и ![]() на каждом процессоре
в один отсортированный блок двойного размера (при исходной упорядоченности блоков
на каждом процессоре
в один отсортированный блок двойного размера (при исходной упорядоченности блоков
![]() и
и ![]() процедура их объединения сводится
к быстрой операции слияния упорядоченных наборов данных);
процедура их объединения сводится
к быстрой операции слияния упорядоченных наборов данных);
-
разделить полученный двойной блок
на две равные части и оставить одну из этих частей (например, с меньшими значениями
данных) на процессоре ![]() , а другую часть (с большими значениями
соответственно) – на процессоре
, а другую часть (с большими значениями
соответственно) – на процессоре ![]()
![]() .
.
Рассмотренная процедура
обычно именуется в литературе как операция "сравнить и разделить"
(compare-split). Следует отметить, что сформированные в результате
такой процедуры блоки на процессорах ![]() и
и ![]() совпадают по размеру с исходными
блоками
совпадают по размеру с исходными
блоками ![]() и
и ![]() и все значения, расположенные
на процессоре
и все значения, расположенные
на процессоре ![]() , являются меньшими значений на
процессоре
, являются меньшими значений на
процессоре ![]() .
.
Алгоритм пузырьковой сортировки [7], общая схема которого представлена в начале данного раздела, в прямом виде достаточно сложен для распараллеливания – сравнение пар значений упорядочиваемого набора данных происходит строго последовательно. В связи с этим для параллельного применения используется не сам этот алгоритм, а его модификация, известная в литературе как метод чет-нечетной перестановки (odd-even transposition) [23]. Суть модификации состоит в том, что в алгоритм сортировки вводятся два разных правила выполнения итераций метода – в зависимости от четности или нечетности номера итерации сортировки для обработки выбираются элементы с четными или нечетными индексами соответственно, сравнение выделяемых значений всегда осуществляется с их правыми соседними элементами. Т.е., на всех нечетных итерациях сравниваются пары
![]() ,
, ![]() ,…,
,…, ![]() (при четном
(при четном
![]() ),
),
на четных итерациях обрабатываются элементы
![]() ,
, ![]() ,…,
,…, ![]() .
.
После ![]() -кратного
повторения подобных итераций сортировки исходный набор данных оказывается упорядоченным.
-кратного
повторения подобных итераций сортировки исходный набор данных оказывается упорядоченным.
Получение параллельного
варианта для метода чет-нечетной перестановки уже не представляет каких-либо
затруднений – сравнение пар значений на итерациях сортировки любого типа являются
независимыми и могут быть выполнены параллельно. Для пояснений такого параллельного
способа сортировки в табл. 4.1 приведен пример упорядочения данных при ![]() ,
, ![]() (т.е. блок значений на каждом
процессоре содержит
(т.е. блок значений на каждом
процессоре содержит ![]() элементов). В первом столбце таблицы
приводится номер и тип итерации метода, перечисляются пары процессоров, для
которых параллельно выполняются операция "сравнить и разделить"; взаимодействующие
пары процессоров выделены в таблице двойной рамкой. Для каждого шага сортировки
показано состояние упорядочиваемого набора данных до и после выполнения итерации.
элементов). В первом столбце таблицы
приводится номер и тип итерации метода, перечисляются пары процессоров, для
которых параллельно выполняются операция "сравнить и разделить"; взаимодействующие
пары процессоров выделены в таблице двойной рамкой. Для каждого шага сортировки
показано состояние упорядочиваемого набора данных до и после выполнения итерации.
Таблица 4.1. Пример сортировки данных параллельным методом чет-нечетной перестановки
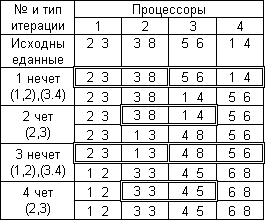
Следует отметить, что в приведенном примере последняя итерация сортировки является избыточной – упорядоченный набор данных был получен уже на третьей итерации алгоритма. В общем случае выполнение параллельного метода может быть прекращено, если в течение каких-либо двух последовательных итераций сортировки состояние упорядочиваемого набора данных не было изменено. Как результат, общее количество итераций может быть сокращено и для фиксации таких моментов необходимо введение некоторого управляющего процессора, который определял бы состояние системы после выполнения каждой итерации сортировки. Однако трудоемкость такой коммуникационной операции (сборка на одном процессоре сообщений от всех процессоров) может оказаться столь значительной, что весь эффект от возможного сокращения итераций сортировки будет поглощен затратами на реализацию операций межпроцессорной передачи данных.
Оценим трудоемкость рассмотренного параллельного метода.
Длительность операций передач данных между процессорами полностью определяется
физической топологией вычислительной сети. Если логически-соседние процессоры,
участвующие в выполнении операций "сравнить и разделить", являются
близкими фактически (например, для линейки или кольца эти процессоры имеют прямые
линии связи), общая коммуникационная сложность алгоритма пропорциональна количеству
упорядочиваемых данных, т.е. ![]() . Вычислительная трудоемкость
алгоритма определяется выражением
. Вычислительная трудоемкость
алгоритма определяется выражением
![]() ,
,
где первая часть соотношения
учитывает сложность первоначальной сортировки блоков, а вторая величина задает
общее количество операций для слияния блоков в ходе исполнения операций "сравнить
и разделить" (слияние двух блоков требует ![]() операций, всего выполняется
операций, всего выполняется ![]() итераций сортировки). С учетом
данной оценки показатели эффективности параллельного алгоритма имеют вид:
итераций сортировки). С учетом
данной оценки показатели эффективности параллельного алгоритма имеют вид:
![]() ,
, ![]()
(в приведенных соотношениях
для величины ![]() использовалась оценка трудоемкости
для наиболее эффективных последовательных алгоритмов сортировки). Анализ выражений
показывает, что если количество процессоров совпадает с числом сортируемых данных
(т.е.
использовалась оценка трудоемкости
для наиболее эффективных последовательных алгоритмов сортировки). Анализ выражений
показывает, что если количество процессоров совпадает с числом сортируемых данных
(т.е. ![]() ), эффективность использования
процессоров падает с ростом
), эффективность использования
процессоров падает с ростом ![]() ; получение асимптотически ненулевого
значения показателя
; получение асимптотически ненулевого
значения показателя ![]() может быть обеспечено при количестве
процессоров, пропорциональных величине
может быть обеспечено при количестве
процессоров, пропорциональных величине ![]() .
.
Детальное описание алгоритма Шелла может быть получено, например, в [7]; здесь же отметим только, что общая идея метода состоит в сравнении на начальных стадиях сортировки пар значений, располагаемых достаточно далеко друг от друга в упорядочиваемом наборе данных. Такая модификация метода сортировки позволяет быстро переставлять далекие неупорядоченные пары значений (сортировка таких пар обычно требует большого количества перестановок, если используется сравнение только соседних элементов).
Для алгоритма Шелла может быть предложен параллельный
аналог метода, если топология коммуникационный сети имеет структуру ![]() -мерного гиперкуба
(т.е. количество процессоров равно
-мерного гиперкуба
(т.е. количество процессоров равно ![]() ). Выполнение сортировки в таком
случае может быть разделено на два последовательных этапа. На первом этапе (
). Выполнение сортировки в таком
случае может быть разделено на два последовательных этапа. На первом этапе (![]() итераций) осуществляется
взаимодействие процессоров, являющихся соседними в структуре гиперкуба (но эти
процессоры могут оказаться далекими при линейной нумерации; для установления
соответствия двух систем нумерации процессоров может быть использован, как и
ранее, код Грея). Второй этап состоит в реализации обычных итераций параллельного
алгоритма чет-нечетной перестановки. Итерации данного этапа выполняются до прекращения
фактического изменения сортируемого набора и, тем самым, общее количество
итераций) осуществляется
взаимодействие процессоров, являющихся соседними в структуре гиперкуба (но эти
процессоры могут оказаться далекими при линейной нумерации; для установления
соответствия двух систем нумерации процессоров может быть использован, как и
ранее, код Грея). Второй этап состоит в реализации обычных итераций параллельного
алгоритма чет-нечетной перестановки. Итерации данного этапа выполняются до прекращения
фактического изменения сортируемого набора и, тем самым, общее количество ![]() таких итераций может быть различным
- от 2 до
таких итераций может быть различным
- от 2 до ![]() . Трудоемкость параллельного варианта
алгоритма Шелла определяется выражением:
. Трудоемкость параллельного варианта
алгоритма Шелла определяется выражением:
![]() ,
,
где вторая и третья
части соотношения фиксируют вычислительную сложность первого и второго этапов
сортировки соответственно. Как можно заметить, эффективность данного параллельного
способа сортировки оказывается лучше показателей обычного алгоритма чет-нечетной
перестановки при ![]() .
.
При кратком изложении
алгоритм быстрой сортировки (полное описание метода содержится, например,
в [23]) основывается на последовательном разделении сортируемого набора данных
на блоки меньшего размера таким образом, что между значениями разных блоков
обеспечивается отношение упорядоченности (для любой пары блоков существует блок,
все значения которого будут меньше значений другого блока). На первой итерации
метода осуществляется деление исходного набора данных на первые две части –
для организации такого деления выбирается некоторый ведущий элемент и
все значения набора, меньшие ведущего элемента, переносятся в первый формируемый
блок, все остальные значения образуют второй блок набора. На второй итерации
сортировки описанные правила применяются последовательно для обоих сформированных
блоков и т.д. После выполнения ![]() итераций исходный массив
данных оказывается упорядоченным.
итераций исходный массив
данных оказывается упорядоченным.
Эффективность быстрой сортировки в значительной степени
определяется успешностью выбора ведущих элементов при формировании блоков. В
худшем случае трудоемкость метода имеет тот же порядок сложности, что и пузырьковая
сортировка (т.е. ![]() ). При оптимальном выборе ведущих
элементов, когда разделение каждого блока происходит на равные по размеру части,
трудоемкость алгоритма совпадает с быстродействием наиболее эффективных способов
сортировки (
). При оптимальном выборе ведущих
элементов, когда разделение каждого блока происходит на равные по размеру части,
трудоемкость алгоритма совпадает с быстродействием наиболее эффективных способов
сортировки (![]() ). В среднем случае количество
операций, выполняемых алгоритмом быстрой сортировки, определяется выражением
[7]:
). В среднем случае количество
операций, выполняемых алгоритмом быстрой сортировки, определяется выражением
[7]:
![]() .
.
Параллельное обобщение алгоритма быстрой сортировки наиболее простым способом
может быть получено для вычислительной системы с топологией в виде ![]() -мерного гиперкуба
(т.е.
-мерного гиперкуба
(т.е. ![]() ). Пусть, как и ранее, исходный
набор данных распределен между процессорами блоками одинакового размера
). Пусть, как и ранее, исходный
набор данных распределен между процессорами блоками одинакового размера ![]() ; результирующее
расположение блоков должно соответствовать нумерации процессоров гиперкуба.
Возможный способ выполнения первой итерации параллельного метода при таких условиях
может состоять в следующем:
; результирующее
расположение блоков должно соответствовать нумерации процессоров гиперкуба.
Возможный способ выполнения первой итерации параллельного метода при таких условиях
может состоять в следующем:
- выбрать каким-либо образом ведущий элемент и разослать его по всем процессорам системы;
- разделить на каждом процессоре имеющийся блок данных на две части с использованием полученного ведущего элемента;
-
образовать пары процессоров, для
которых битовое представление номеров отличается только в позиции ![]() , и осуществить
взаимообмен данными между этими процессорами; в результате таких пересылок данных
на процессорах, для которых в битовом представлении номера бит позиции
, и осуществить
взаимообмен данными между этими процессорами; в результате таких пересылок данных
на процессорах, для которых в битовом представлении номера бит позиции ![]() равен 0, должны оказаться части блоков со значениями, меньшими ведущего элемента;
процессоры с номерами, в которых бит
равен 0, должны оказаться части блоков со значениями, меньшими ведущего элемента;
процессоры с номерами, в которых бит ![]() равен 1, должны собрать, соответственно,
все значения данных, превышающие значение ведущего элемента.
равен 1, должны собрать, соответственно,
все значения данных, превышающие значение ведущего элемента.
В результате выполнения такой итерации сортировки исходный набор оказывается
разделенным на две части, одна из которых (со значениями меньшими, чем значение
ведущего элемента) располагается на процессорах, в битовом представлении номеров
которых бит ![]() равен 0. Таких процессоров всего
равен 0. Таких процессоров всего
![]() и, таким образом, исходный
и, таким образом, исходный ![]() -мерный гиперкуб также оказывается
разделенным на два гиперкуба размерности
-мерный гиперкуб также оказывается
разделенным на два гиперкуба размерности ![]() . К этим подгиперкубам,
в свою очередь, может быть параллельно применена описанная выше процедура. После
. К этим подгиперкубам,
в свою очередь, может быть параллельно применена описанная выше процедура. После
![]() -кратного
повторения подобных итераций для завершения сортировки достаточно упорядочить
блоки данных, получившиеся на каждом отдельном процессоре вычислительной системы.
Для пояснения на рис. 4.11 представлен пример упорядочивания данных при
-кратного
повторения подобных итераций для завершения сортировки достаточно упорядочить
блоки данных, получившиеся на каждом отдельном процессоре вычислительной системы.
Для пояснения на рис. 4.11 представлен пример упорядочивания данных при ![]() ,
,
![]() (т.е. блок каждого
процессора содержит 4 элемента). На этом рисунке процессоры изображены в виде
прямоугольников, внутри которых показано содержимое упорядочиваемых блоков данных;
значения блоков приводятся в начале и при завершении каждой итерации сортировки.
Взаимодействующие пары процессоров соединены двунаправленными стрелками. Для
разделения данных выбирались наилучшие значения ведущих элементов: на первой
итерации для всех процессоров использовалось значение 0, на второй итерации
для пары процессоров 0, 1 ведущий элемент равен 4, для пары процессоров 2, 3
это значение было принято равным –5.
(т.е. блок каждого
процессора содержит 4 элемента). На этом рисунке процессоры изображены в виде
прямоугольников, внутри которых показано содержимое упорядочиваемых блоков данных;
значения блоков приводятся в начале и при завершении каждой итерации сортировки.
Взаимодействующие пары процессоров соединены двунаправленными стрелками. Для
разделения данных выбирались наилучшие значения ведущих элементов: на первой
итерации для всех процессоров использовалось значение 0, на второй итерации
для пары процессоров 0, 1 ведущий элемент равен 4, для пары процессоров 2, 3
это значение было принято равным –5.
Эффективность параллельного метода быстрой сортировки, как и в последовательном варианте, во многом зависит от успешности выбора значений ведущих элементов. Определение общего правила для выбора этих значений не представляется возможным; сложность такого выбора может быть снижена, если выполнить упорядочение локальных блоков процессоров перед началом сортировки и обеспечить однородное распределение сортируемых данных между процессорами вычислительной системы.
Длительность выполняемых операций передачи данных определяется операцией
рассылки ведущего элемента на каждой итерации сортировки - общее количество
межпроцессорных обменов для этой операции на ![]() -мерном гиперкубе может
быть ограничено оценкой
-мерном гиперкубе может
быть ограничено оценкой
![]() ,
,
и взаимообменом частей
блоков между соседними парами процессоров – общее количество таких передач совпадает
с количеством итераций сортировки, т.е. равно ![]() , объем передаваемых
данных не превышает удвоенного объема процессорного блока, т.е. ограничен величиной
, объем передаваемых
данных не превышает удвоенного объема процессорного блока, т.е. ограничен величиной
![]() .
.
Вычислительная трудоемкость метода обуславливается сложностью локальной сортировки процессорных блоков, временем выбора ведущих элементов и сложностью разделения блоков, что в целом может быть выражено при помощи соотношения:
![]()
(при построении данной оценки предполагалось, что для выбора значения ведущего элемента при упорядоченности процессорных блоков данных достаточно одной операции).
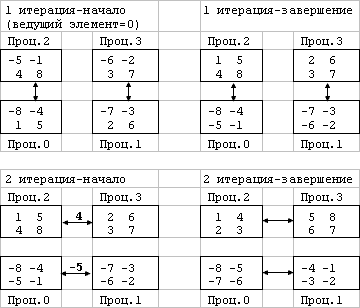
Рис. 4.11. Пример упорядочивания данных параллельным методом быстрой сортировки (без результатов локальной сортировки блоков)
Математические модели в виде графов широко используются при моделировании разнообразных явлений, процессов и систем. Как результат, многие теоретические и реальные прикладные задачи могут быть решены при помощи тех или иных процедур анализа графовых моделей. Среди множества этих процедур может быть выделен некоторый определенный набор типовых алгоритмов обработки графов. Рассмотрению вопросов теории графов, алгоритмов моделирования, анализа и решения задач на графах посвящено достаточно много различных изданий, в качестве возможного руководства по данной тематике может быть рекомендована работа [8].
Пусть, как и ранее во 2 разделе пособия,
![]() есть граф
есть граф
![]() ,
,
для которого набор вершин ![]() ,
, ![]() , задается множеством
, задается множеством
![]() ,
а список дуг графа
,
а список дуг графа
![]() ,
, ![]() ,
,
определяется множеством ![]() . В общем случае
дугам графа могут приписываться некоторые числовые характеристики
. В общем случае
дугам графа могут приписываться некоторые числовые характеристики ![]() ,
, ![]() (взвешенный
граф).
(взвешенный
граф).
Для описания графов известны различные
способы задания. При малом количестве дуг в графе (т.е. ![]() )
целесообразно использовать для определения графов списки, перечисляющие
имеющиеся в графах дуги. Представление достаточно плотных графов, для
которых почти все вершины соединены между собой дугами (т.е.
)
целесообразно использовать для определения графов списки, перечисляющие
имеющиеся в графах дуги. Представление достаточно плотных графов, для
которых почти все вершины соединены между собой дугами (т.е. ![]() ), может быть эффективно
обеспечено при помощи матрицы инцидентности
), может быть эффективно
обеспечено при помощи матрицы инцидентности
![]() ,
, ![]() ,
,
ненулевые значения элементов которой соответствуют дугам графа
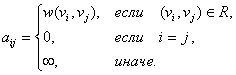
Использование матрицы инцидентности позволяет использовать также при реализации вычислительных процедур для графов матричные алгоритмы обработки данных.
Далее в пособии обсуждаются параллельные способы решения двух типовых задач на графах – нахождение минимально охватывающих деревьев и поиск кратчайших путей. Для представления графов используется способ задания при помощи матриц инцидентности.
Охватывающим деревом (или остовом)
неориентированного графа ![]() называется подграф
называется подграф ![]() графа
графа ![]() , который является
деревом и содержит все вершины из
, который является
деревом и содержит все вершины из ![]() . Определив вес подграфа для взвешенного
графа как сумму весов входящих в подграф дуг, тогда под минимально
охватывающим деревом (МОД)
. Определив вес подграфа для взвешенного
графа как сумму весов входящих в подграф дуг, тогда под минимально
охватывающим деревом (МОД) ![]() будем понимать охватывающее дерево
минимального веса. Содержательная интерпретация задачи нахождения МОД
может состоять, например, в практическом примере построения локальной
сети персональных компьютеров с прокладыванием наименьшего количества
соединительных линий связи.
будем понимать охватывающее дерево
минимального веса. Содержательная интерпретация задачи нахождения МОД
может состоять, например, в практическом примере построения локальной
сети персональных компьютеров с прокладыванием наименьшего количества
соединительных линий связи.
Дадим краткое описание алгоритма решения поставленной задачи, известного
под названием метода Прима (Prim) [8].
Алгоритм начинает работу с произвольной вершины графа, выбираемого в
качестве корня дерева, и в ходе последовательно выполняемых итераций
расширяет конструируемое дерево до МОД. Пусть ![]() есть множество вершин, уже включенных
алгоритмом в МОД, а величины
есть множество вершин, уже включенных
алгоритмом в МОД, а величины ![]() ,
,
![]() , характеризуют дуги минимальной
длины от вершин, еще не включенных в дерево, до множества
, характеризуют дуги минимальной
длины от вершин, еще не включенных в дерево, до множества ![]() , т.е.
, т.е.
![]()
(если для какой либо вершины ![]() не существует ни одной
дуги в
не существует ни одной
дуги в ![]() , значение
, значение ![]() устанавливается в
устанавливается в ![]() ). В начале работы алгоритма выбирается
корневая вершина МОД
). В начале работы алгоритма выбирается
корневая вершина МОД ![]() и полагается
и полагается
![]() ,
,
![]() .
.
Действия, выполняемые на каждой итерации алгоритма Прима, состоят в следующем:
-
определяются значения величин
![]() для всех вершин, еще не включенные в состав МОД;
для всех вершин, еще не включенные в состав МОД;
-
выбирается вершина ![]() графа
графа ![]() , имеющая дугу
минимального веса до множества
, имеющая дугу
минимального веса до множества ![]()
![]() ;
;
-
включение выбранной вершины
![]() в
в ![]() .
.
После выполнения ![]() итераций метода МОД будет сформировано;
вес этого дерева может быть получен при помощи выражения
итераций метода МОД будет сформировано;
вес этого дерева может быть получен при помощи выражения
![]() .
.
Трудоемкость
нахождения МОД характеризуется квадратичной зависимостью от числа вершин
графа ![]()
![]() .
.
Оценим возможности для параллельного выполнения рассмотренного алгоритма
нахождения минимально охватывающего дерева. Итерации метода должны выполняться
последовательно и, тем самым, не могут быть распараллелены. С другой
стороны, выполняемые на каждой итерации алгоритма действия являются
независимыми и могут реализовываться одновременно. Так, например, определение
величин ![]() может осуществляться для каждой вершины графа в отдельности, нахождение
дуги минимального веса может быть реализовано по каскадной схеме и т.д.
может осуществляться для каждой вершины графа в отдельности, нахождение
дуги минимального веса может быть реализовано по каскадной схеме и т.д.
Распределение данных между процессорами вычислительной системы должно
обеспечивать независимость перечисленных операций алгоритма Прима. В
частности, это может быть обеспечено, если каждая вершина графа располагается
на процессоре вместе со всей связанной с вершиной информацией. Соблюдение
данного принципа приводит к тому, что при равномерной загрузке каждый
процессор ![]() ,
, ![]() , будет содержать
набор вершин
, будет содержать
набор вершин
![]() ,
, ![]() ,
, ![]() ,
,
соответствующий
этому набору блок из ![]() величин
величин ![]() ,
, ![]() ,
и вертикальную полосу матрицы инцидентности графа
,
и вертикальную полосу матрицы инцидентности графа ![]() из
из ![]() соседних столбцов, а
также общую часть набора
соседних столбцов, а
также общую часть набора ![]() и формируемого в процессе вычислений
множества вершин
и формируемого в процессе вычислений
множества вершин ![]() .
.
С учетом такого разделения данных итерация параллельного варианта алгоритма Прима состоит в следующем:
-
определяются значения величин
![]() для всех вершин, еще не включенные в состав МОД; данные вычисления выполняются
независимо на каждом процессоре в отдельности; трудоемкость такой операции
ограничивается сверху величиной
для всех вершин, еще не включенные в состав МОД; данные вычисления выполняются
независимо на каждом процессоре в отдельности; трудоемкость такой операции
ограничивается сверху величиной ![]() (на первой итерации алгоритма
необходим перебор всех вершин, что требует вычислений порядка
(на первой итерации алгоритма
необходим перебор всех вершин, что требует вычислений порядка ![]() );
);
-
выбирается вершина ![]() графа
графа ![]() , имеющая дугу
минимального веса до множества
, имеющая дугу
минимального веса до множества ![]() ; для выбора такой вершины необходимо
осуществить поиск минимума в наборах величин
; для выбора такой вершины необходимо
осуществить поиск минимума в наборах величин ![]() , имеющихся на каждом из процессоров (количество параллельных операций
, имеющихся на каждом из процессоров (количество параллельных операций
![]() ), и выполнить
сборку полученных значений (длительность такой операции передачи данных
на гиперкубе, например, пропорциональна величине
), и выполнить
сборку полученных значений (длительность такой операции передачи данных
на гиперкубе, например, пропорциональна величине ![]() );
);
-
рассылка номера выбранной
вершины для включения в охватывающее дерево всем процессорам (для гиперкуба
сложность этой операции также определяется величиной ![]() ).
).
Получение МОД обеспечивается при выполнении ![]() итераций алгоритма Прима;
как результат, общая трудоемкость метода определяется соотношением
итераций алгоритма Прима;
как результат, общая трудоемкость метода определяется соотношением
![]() .
.
С учетом данной оценки показатели эффективности параллельного алгоритма имеют вид:
![]() ,
, ![]() .
.
Анализ выражений показывает, что достижение асимптотически ненулевого
значения показателя ![]() становится возможным при количестве
процессоров, пропорциональном величине
становится возможным при количестве
процессоров, пропорциональном величине ![]() .
.
Задача поиска кратчайших путей
на графе состоит в нахождении путей минимального веса от некоторой заданной
вершины ![]() до всех имеющихся вершин графа. Постановка подобной проблемы имеет важное
практическое значение в различных приложениях, когда веса дуг означают
время, стоимость, расстояние, затраты и т.п.
до всех имеющихся вершин графа. Постановка подобной проблемы имеет важное
практическое значение в различных приложениях, когда веса дуг означают
время, стоимость, расстояние, затраты и т.п.
Возможный способ решения поставленной задачи, известный
как алгоритм Дейкстры [8], практически совпадает с методом Прима.
Различие состоит лишь в интерпретации и в правиле оценки вспомогательных
величин ![]() ,
, ![]() .
В алгоритме Дейкстры эти величины означают суммарный вес пути от начальной
вершины до всех остальных вершин графа. Как результат, после выбора
очередной вершины
.
В алгоритме Дейкстры эти величины означают суммарный вес пути от начальной
вершины до всех остальных вершин графа. Как результат, после выбора
очередной вершины ![]() графа для включения в множество выбранных вершин
графа для включения в множество выбранных вершин ![]() , значения величин
, значения величин ![]() ,
, ![]() ,
пересчитываются в соответствии с новым правилом:
,
пересчитываются в соответствии с новым правилом:
![]() .
.
С учетом измененного правила пересчета величин ![]() ,
, ![]() ,
схема параллельного выполнения алгоритма Дейкстры может быть сформирована
по аналогии с параллельным вариантом метода Прима. Конкретизация такой
схемы и определение показателей эффективности метода для разных топологий
вычислительной системы могут рассматриваться как темы самостоятельных
заданий. Для сравнения в табл. 4.2 приводятся оценки числа процессоров,
при которых достигается асимптотически ненулевые значения эффективности,
для топологий кольца, решетки и гиперкуба.
,
схема параллельного выполнения алгоритма Дейкстры может быть сформирована
по аналогии с параллельным вариантом метода Прима. Конкретизация такой
схемы и определение показателей эффективности метода для разных топологий
вычислительной системы могут рассматриваться как темы самостоятельных
заданий. Для сравнения в табл. 4.2 приводятся оценки числа процессоров,
при которых достигается асимптотически ненулевые значения эффективности,
для топологий кольца, решетки и гиперкуба.
Таблица 4.2. Показатели эффективности алгоритмов Прима и Дейкстры для разных топологий
